Review: Asset allocation with factor-based covariance matrices
해당 게시글은 Conlon et al,(2025)의 “Asset allocation with factor-based covariance matrices” 논문을 리뷰한 글입니다. 본 게시물에서 인용한 논문 및 자료에 대한 상세 정보는 아래의 링크를 통해 확인하실 수 있습니다.
Conlon et al,(2025)
연구실에 합류한지 어느덧 세 달이 되어가고, 연구 과제 관련 주제인 Decision-Focused Learning과 나의 관심 분야였던 factor model을 결합할 연구가 없는지 고민하던 중 해당 논문에 대해 읽어보면서 어느정도 방향성을 정할 수 있었던 것 같다.
앞으로 연구를 계속 이어감에 있어서 주요 레퍼런스가 될 논문이기에 자세하게 읽을 겸 리뷰를 진행해보고자 한다.
1. Introduction
이 논문에서는 공분산 행렬을 구성하는 방법 중 대표적으로 활용되는 팩터 모델이 GMV 성과를 향상시킬 수 있는지 분석한다.
Markowitz(1952) 의 평균-분산 프레임워크, 즉 포트폴리오 최적화의 경우 추정해야 할 파라미터가 존재하며, 그중 대표적으로 자산의 기대수익률이 있다.
→ 그러나 기대수익률 추정은 너무 어렵고, 추정 오류가 약간만 있어도 가중치가 극단적으로 가는 코너해 문제가 있기 때문에 Kolm, Tütüncü, Fabozzi(2014)가 수익률 추정 없이 리스크 지표(대표적으로 자산의 공분산 행렬)만을 사용하는 방법을 제시한다.
문제는 자산의 공분산 행렬을 추정하는 것도 굉장히 어렵다는 것. 대표적으로 과거 표본값들을 사용하여 공분산을 추정하지만 자산이 증가할수록 추정해야 할 원소의 수가 기하급수적으로 늘어난다는 점, 그리고 자산이 관측 시점 수보다 클 경우 공분산 행렬이 singular 해진다는 문제가 있다.
→ 팩터모델은 이러한 단점을 극복하는 좋은 방법이다. 자산 개수 N을 팩터 개수 K로 차원축소하는 효과가 있기 때문에 singular의 문제를 해결할 수 있으며, 추정 원소 수가 줄어들기 때문에 추정 안정성 또한 높아진다.
팩터 모델은 관측 가능한 팩터모델(ex. Fama-French 3 factor models)과 관측되지 않는 잠재 팩터모델(latent factor model)이 있는데, 해당 논문에서는 latent factor model을 활용한 공분산 추정에 중점을 두고 분석을 진행했다.
※ 관련 문헌 분석
- Moskowitz(2003)
- Size 팩터는 자산의 공분산 구조를 설명하는 데 효과적임.
- 반면 Value 팩터는 공분산 구조와의 연관성이 상대적으로 약했음.
- Momentum 팩터는 수익률의 이차 모멘트와는 관련이 없다 → 공분산 구조를 잘 설명하지 못한다.
- Fan(2008), Fan, Lv(2008)
- 공분산 행렬을 추정하기 위해 팩터 모델 기반 접근법을 사용하는 것에 대한 효과를 보임.
- Fan, Liao, Mincheva(2011)
- exact factor model과 approximate factor model에 대한 공분산 추정 방법 제안.
- De Nard, Ledoit, Wolf(2021)
- 잔차 공분산을 어떻게 추정하느냐에 따라 포트폴리오 성과가 달라짐을 보임.
- Lassance and Vrins(2021), Lassance, DeMiguel and Vrins(2022)
- ICA(Independent Component Analysis)를 활용하여 uncorrelated한 팩터가 아닌 independent한 팩터를 추출하여 고차 모멘트 및 리스크 패리티를 개선하고자 함.
- Anis & Kwon(2025)
- Decision-Focused Learning을 팩터모델에 적용한 최초의 연구. 카디널리티 제약 하에서 DFL 기반 팩터모델이 GMV의 성과를 향상시킬 수 있음을 보임.
latent factor model은 많은 수의 변수로부터 정보를 간단하게 결합할 수 있다는 장점이 있지만, 일반적으로 사용되는 PCA 및 PLS는 팩터 가중치가 0이 아니기 때문에 고차원 환경에서 추정이 어려워진다.
이 프레임워크의 또다른 단점으로는 변수들 간의 관계가 선형으로 제한된다는 점인데, 이를 해결하기 위해 본 논문에서는 다양한 차원 축소 기법을 적용한다.
특히 소수의 가중치를 가진 latent factor를 생성하는 방법을 통해 팩터 기반 공분산 행렬의 추정을 개선하는데 집중한다.
추가적으로, PCA 및 PLS의 또다른 단점인 선형성 문제를 해결하기 위해 오토인코더로 팩터를 생성하여 비선형성을 반영해준다.
먼저 팩터 기반 공분산 행렬 추정 정확성을 조사하기 위해 1960~2022년까지의 CRSP 데이터베이스 상위 100개 주식에 대한 월별 수익률을 사용한다. 실제 공분산 행렬의 대용값으로 본 논문은 12개월 미래 일일 수익률을 기반으로 한 샘플 추정치를 고려하고, 결과 평가를 위해 다양한 손실함수를 사용한다.
벤치마크로는 샘플 추정치, 선형 및 비선형 shrinkage estimator, Wishart 확률적 공분산 행렬 접근법으로, 결과적으로 MAE, MSE와 같은 대칭 손실함수를 기준으로 보면 대부분의 팩터모델 기반 공분산행렬이 벤치마크보다 정확했다. 또한 비대칭 손실함수 결과에 따르면 팩터모델의 성과 향상의 원인은 벤치마크보다 목표 공분산 행렬을 과대추정하는 경향이 덜했기 때문에라는 것을 알 수 있다.
또한, 팩터모델은 EW 및 VW 포트폴리오 벤치마크와 다른 공분산 추정방식을 기반으로 한 GMV 포트폴리오 성과보다 우수한 결과를 보였다.
특히 다른 벤치마크 방법보다 가중치가 더 작고 시간에 따른 변동이 더 적었으며, 정적 팩터 공분산 버전과 선형 차원축소 방법을 기반으로 한 포트폴리오의 경우 turnover가 낮아 거래비용에 대한 민감도가 줄어들었다.
전반적으로 팩터 모델 기반 포트폴리오는 다른 벤치마크에 비해 표준편차 및 샤프비율 측면에서 거래비용을 고려한 후에도 통계적으로 유의미한 성과를 보였다.
팩터 모델 기반 공분산 행렬 추정방법 간에는 성과 차이가 뚜렷하진 않았으나, 거래비용을 고려한 후에는 정적 팩터 공분산 행렬을 기반으로 한 전략이 샤프비율 측면에서 동적 팩터 공분산 행렬 버전을 능가하는 결과를 보인다.
팩터 모델 기반 포트폴리오는 test assets을 늘려도 EW 벤치마크를 능가하지만, shrinkage estimator보다는 저조한 성과를 보인다.
2. Methodology
2.1. Factor Models
본 논문에서는 latent factor model을 고려하며, 이들은 차원 축소 기법을 사용하여 도출된다.
i = 1 ,…, N 개의 자산, t = 1,…, T 개의 관측값, k = 1,…, K 개의 latent factor를 가진 자산 수익률 $r_{i,t}$ 에 대한 팩터 모델은 다음과 같은 형태를 가진다.
$r_{i,t} = \alpha_i + \beta_i(R_tW) + u_{i,t} = \alpha_i + \beta_iF_t + u_{i,t}$
여기서 $W = (w_1, …, w_k)$ 의 $w_k$ 는 k번째 latent factor인 $f_k$ 를 구성하는 데 사용되는 가중치 벡터이다. 차원 축소 방법으로 latent factor를 추출하면 OLS를 통해 factor loading $\beta_i$ 및 intercept $\alpha_i$ 를 추정할 수 있다.
latent factor를 구성할 때 가장 일반적으로 사용되는 차원 축소 기법은 PCA와 PLS이다.
이 둘은 모두 기존의 고차원 데이터를 선형결합을 통해 저차원으로 표현하는 방법인데, latent factor $f_t$ 를 추출하는 방식에서 차이가 있다.
PCA는 자산 수익률 간의 공분산 구조만을 반영하도록 가중치 행렬 W를 생성함으로써 비지도 학습 방식으로 latent factor를 도출하는 반면, PLS는 target과 가장 높은 상관을 갖는 $R_t$ 의 선형결합 K개를 만들어 지도학습 방식으로 factor를 추출한다.
$PCA: \max_{w} Var(R_t w)$
$PLS: \max_{w} Cov(R_t w, Y_t)$
이 두 방법 모두 가중치 행렬 W의 요소가 0이 아니어서 중요한 변수를 선택하여 팩터를 구성하는 것이 불가능하다.
이러한 문제를 해결하기 위해, 각 latent factor가 원래 변수 중 일부만의 선형결합이 되도록 sparse weight를 가진 수정된 latent factor 추출 방법이 존재한다.
→ SPCA, SPLS 두 방법 모두 L1 및 L2 norm의 조합을 기반으로 하는 패널티를 적용하여 sparse latent factor를 구성할 수 있도록 한다.
추가적으로, 오토인코더(autoencoder)를 사용하여 latent factor를 구성하는데, 이는 비지도 신경망으로 PCA의 비선형 버전이라고 볼 수 있다.
오토인코더는 PCA 및 SPCA와는 다르게 동작하는데, SPCA는 원래 N을 K factor에 선형적으로 매핑하여 차원을 줄이는 방식이라면, 오토인코더는 비선형 활성함수를 통해 데이터의 비선형 표현을 발견한다.
추정 오차를 줄이기 위해 두 가지 유형의 오토인코더가 사용된다.
- 손실함수에 패널티를 추가하는 sparse autoencoders(AEN)
- 무작위 노이즈로 인해 손상된 원본 데이터셋을 재구성하려는 denoising autoencoders(DAE)
본 논문에서는 single hidden layer를 사용하며 본 논문의 목표는 latent factor를 통해 공분산 행렬을 추정하는 것이 목표이므로 해당 목표에 적합한 오토인코더를 사용한다.
※ 오토인코더 구조(appendix)
- Activation function은 tanh 사용
- Loss function: $\min_{b,W} \mathcal{L}(R_t,\hat R_t)= min_{b,W}\Vert R_t-\hat R_t \Vert^2$
- sparse autoencoder(AEN): $\min_{\theta} \Vert R_t - \hat R_t \Vert_F^2 + \lambda_1 \Vert Z_\text{bottleneck} \Vert_1 + \lambda_2 \Vert Z_\text{bottleneck} \Vert_2^2$
- denoising autoencoder의 noise 표준편차 후보: $σ∈$ {0.01,0.1}
- $K∈ [1,5]$
- Adam optimizer 사용
- learning rate = {0.001. 0.01}
- batch size = 32
- epoch = 100
- patience = 25
이때 첫 학습에서는 train : validation = 8: 2 로 설정하여 validation loss가 가장 낮게 나온 하이퍼파라미터 조합을 선정한 후, validation 기간까지 train set으로 사용하여 모델 파라미터를 재학습하는 구조
→ validation loss = $\mathcal{L}_{\text{MVP}}\left(\hat{\omega},\hat{\Sigma}_r\right)=\hat{\omega}^{\prime}\hat{\Sigma}_r\hat{\omega}$
이렇게 추출된 latent factor들은 다시 OLS의 독립변수로 들어가서 팩터 로딩 및 intercept를 추정한다.
2.2. Factor-based covariance matrices
각 방법으로 latent factor를 추출한 후 OLS로 알파와 베타를 모두 추정했다면, 자산 수익률의 공분산 행렬은 두 구성 요소로 분해될 수 있다.
$Σ_r=BʹΣ_fB+Σ_u$
각각 팩터 공분산 및 잔차 공분산 행렬, 그리고 팩터 로딩으로 나타나는데, 본 논문에서는 Fan, Fan and Lv(2008)에서 제안한 exact factor model을 가정한다.
→ 잔차 공분산 행렬의 비대각 요소가 0이 되면서 대각행렬으로 변함.
지금까지 설명한 모델들은 모두 static factor covariance(SFC) 구조에 기반하는데, 본 연구에서는 동적 팩터모델도 고려한다.
→ 팩터 로딩이 시간에 따라 변할 수 있는 모델 or 팩터 공분산 행렬이나 잔차 공분산 행렬 중 하나가 시간에 따라 변하는 모델
- intercept 및 팩터 로딩이 시간에 따라 변하는 경우: dynamic beta covariance(DBC)
- 팩터의 공분산 행렬이 시간에 따라 변하는 경우: dynamic factor covariance(DFC)
- 잔차 공분산 행렬이 시간에 따라 변하는 경우: dynamic error covariance(DEC)
정적 모델에서는 자산의 베타(팩터 로딩)가 추정 기간 동안 일정하다고 가정하지만, 실제로 베타는 시간에 따라 변하는 경우가 많기 때문에 현실성이 부족한다는 문제가 있다.
따라서 본 연구에서는 시간 가변적인 팩터 로딩 추정 방식을 고려한다.
intercept $\alpha_i$ 와 factor loading $\beta_i$ 가 시간에 따라 변할 수 있도록 할 때, conditional dynamic factor model은 다음과 같은 형태를 가진다.
$r_{i,t}=a_{i,t}+β_{i,t}F_t+u_{i,t}$
이때 OLS에서 $\hat \beta_i = \hat \sum_f^{-1} \hat \sigma_{fr_i}$ 이므로, 시간에 따라 변하도록 하면 $\hat \beta_{i,t} = \hat \sum_{f,t}^{-1} \hat \sigma_{fr_i,t}$ 로 표현된다.
따라서 시간에 따라 변하는 공분산 행렬은 다음과 같다.
$Σ_{r,t}=B_t’ Σ_fB_t+Σ_u$
또한 DFC 및 DEC 하에서는 각각 팩터 공분산 행렬, 잔차 공분산 행렬이 시간에 따라 변하기 때문에 다음과 같이 자산 공분산 행렬을 구할 수 있다.
$Σ_{r,t}=BʹΣ_{f,t}B+Σ_u$
$Σ_{r,t}=BʹΣ_fB+Σ_{u,t}$
이때 팩터 공분산 $Σ_{f,t}$ 은 dynamic conditional correlation(DCC) 모델에 의해 추정되며, 잔차 분산 $Σ_{u,t}$ 은 단변량 GARCH 모델에 의해 추정된다.
2.3. Minimum-Variance portfolios
각 팩터모델이 추정한 공분산 행렬의 경제적 가치를 조사하기 위해 본 논문에서는 최소-분산 포트폴리오를 사용한다.
본 논문에서 사용하는 GMV의 목적함수는 가장 기본 방식과 long-only 제약 추가버전, 거래비용을 반영한 turnover 제약 추가버전이 있다.
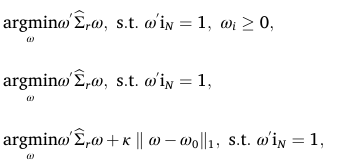
이때 적용되는 거래비용은 κ = 10bps으로 설정한다.
2.4. Benchmark models
벤치마크 모델로는 먼저 동일가중 포트폴리오(EW), 시가총액을 기반으로 하는 가치가중 포트폴리오(VW) 이외에 공분산 행렬의 4가지 추정치를 이용한 최소-분산 포트폴리오를 고려한다.
- Ledoit and Wolf(2004)의 linear shrinkage(LINS) covariance
- Ledoit and Wolf(2017)의 non-linear shrinkage(NLS) covariance
- Moura, Santos and Ruiz(2020)의 Wishart stochastic(Wishart) covariance
(2, 3번째 결과는 Internet Appendix에 나와있음.)
3. Data and sample splitting
데이터는 1960년 1월부터 2022년 12월까지 CRSP 월별 주식 수익률을 사용했으며 각 종목은 T = 756 의 월별 관측값으로 구성되어 있다.
또한 소형주로 인한 문제를 완화하기 위해 NYSE, AMEX, NASDAQ 증권거래소에 상장된 주식 중 1달러 이상의 보통주를 대상으로 하였다.
OOS 성과 평가를 위해 롤링 윈도우 방식으로 모델이 학습되며, 롤링 윈도우 크기는 $T_0 = 240$ 으로 설정하였다.
이후 한 달씩 이동하며, 따라서 OOS 기간은 총 505개월(1980.01 ~ 2022.01)이다.
각 롤링 윈도우 반복 시점마다 포트폴리오가 구성되며, 이때 해당 롤링 윈도우 안에서 수익률 데이터가 최소 97.5% 이상 존재하는 주식만 포함하며, 결측값은 해당 시계열의 평균값으로 대체한다.
앞선 롤링 윈도우가 종료되면 다음 달 수익률 관측치가 존재하는 주식만 다음 롤링 윈도우에 사용된다.
test assets은 각 롤링 윈도우 시점마다 시가총액이 가장 큰 100개 종목을 대상으로 하였으며, 추가 분석에서 더 큰 규모로 확장한다.
자산수익률의 경우 각 시점에서 해당 종목의 순위를 계산한 뒤, 그 순위를 관측치 수로 나누고 0.5를 빼서 [-0.5,0.5] 범위에 있도록 한다.
→ 이러한 rank transformation은 순서 정보에 초점을 맞추어 이상치에 덜 민감하다는 장점이 있음.
4. Empirical results
4.1. Forecast evaluation
true covariance 행렬을 관측하는 것은 불가능하기에, 모델의 예측 정확도는 사후 추정치 $S_t$ 를 기반으로 측정해야한다.
각 반복마다 미래 1년동안의 일일 수익률을 기반으로 한 샘플 공분산 행렬을 사용하여 $S_t$를 근사한다.
이렇게 구성된 true covariance와 각 latent factor model로 추정한 covariance를 4가지 손실함수를 기반으로 비교한다.
먼저 과소예측과 과대예측에 대한 패널티 정도가 다르지 않은 2개의 대칭 손실함수는 다음과 같다.
- Mean Squared Error(MSE)
- Mean Absolute Error(MAE)
추가적으로 고려하는 2개의 손실함수는 과소예측 및 과대예측에 대해 비대칭적인 특징을 가진다.
- quasi-likelihood function(QLK)
- 과소예측에 대해 강하게 패널티를 부과
$\text{QLK} = \log \hat{\Sigma}_t + \mathbf{i}’(\hat \Sigma_t^{-1} \odot \hat{S}_t)\mathbf{i}$
- ASYM
- 과대예측에 대해 강하게 패널티를 부과
- $\text{ASYM} = \frac{1}{b(b-1)} \text{tr}\left(\hat{S}_t^b - \hat{\Sigma}_t^b\right) - \frac{1}{b-1} \text{tr}\left[\hat{\Sigma}_t^{b-1}(\hat{\Sigma}_t - \hat{S}_t)\right]$
- b = 3으로 설정
모든 지표에서 값이 낮을수록 바람직하며, 추가적으로 linear shrinkage 기반 공분산과 비교하여 통계적으로 유의한 성과를 거두었는지 검정한다.
two-sided p-value는 최대 12개월 시차까지 자기상관을 조정한다.
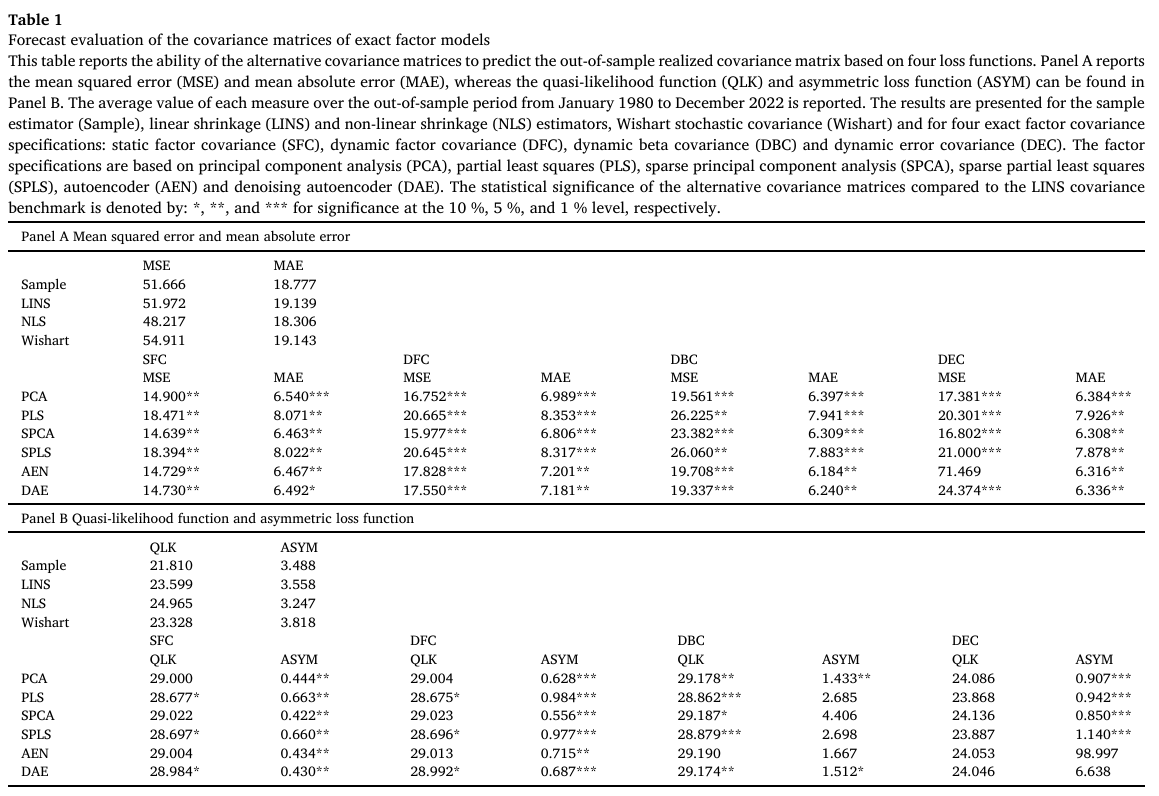
Table 1의 Panel A는 대칭 손실함수인 MAE, MSE을 기반으로 한 공분산 행렬 추정능력 비교 결과이다.
- 대부분의 latent factor model 기반 공분산 행렬이 나머지 공분산 행렬에 비해 두 손실함수 모두 더 낮은 값을 생성하며, LINS 기준치에 비해 통계적으로 유의미한 결과를 나타낸다.
- 비지도 학습 방법(PCA, SPCA, AEN, DAE)이 지도 학습 방법(PLS, SPLS)보다 12개월 이후의 공분산 행렬을 예측하는 데 더 우수하다.
- 가장 낮은 MSE 및 MAE 값을 가지는 공분산 행렬은 정적 팩터 공분산 구조(SFC) 또는 팩터 공분산 및 잔차 공분산이 시간에 따라 변하도록 허용한 경우(DFC, DEC)였다.
- AEN factor를 기반으로 한 DEC 모델은 팩터모델 중 유일하게 벤치마크보다 더 높은 MSE 값을 보였다.
Panel B는 QLK 및 ASYM 손실함수에 따른 예측성능을 비교한 결과이다.
- ASYM 값이 벤치마크보다 낮다는 점은 팩터모델 기반 공분산이 과대예측되는 정도가 낮다는 것을 의미한다.
- SFC, DFC 구조 및 PCA 기반 dynamic beta covariance, 선형 차원축소 방법에 기반한 dynamic error covariance가 벤치마크 대비 통계적으로 유의한 결과를 보였다.
- 벤치마크 공분산의 경우 팩터 모델 기반 공분산보다 낮은 QLK 값을 가졌지만, 통계적으로는 유의하지 않았다.
4.2. Portfolio performance
팩터 모델 기반 공분산 행렬의 경제적 가치를 분석하기 위해, 본 논문에서는 최소-분산 포트폴리오의 성과를 비교한다.
주요 평가지표는 포트폴리오의 수익률 표준편차이며, 추가적으로 샤프비율을 고려한다.
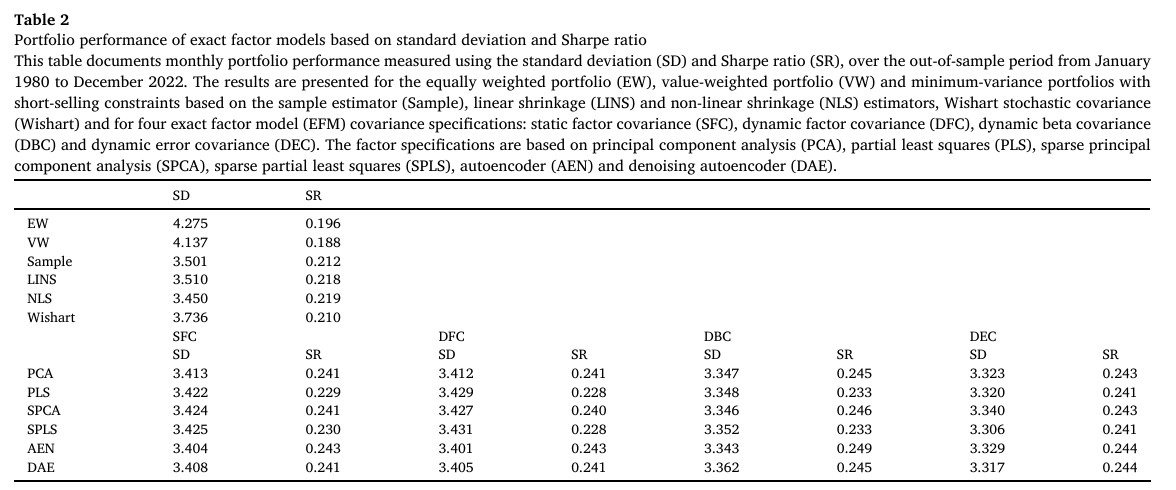
Table 2는 505개 OOS 포트폴리오 초과수익률의 월별 표준편차와 샤프비율을 나타낸 표이다.
- 최적 포트폴리오들은 표준편차 및 샤프비율 측면에서 EW 및 VW 포트폴리오를 일관되게 큰 폭으로 상회한다.
- 벤치마크 공분산 행렬 중에서는 NLS가 가장 낮은 표준편차와 가장 높은 샤프비율을 보였다.
- 팩터모델 기반 공분산 행렬을 사용하면, NLS 대비 포트폴리오 위험을 최대 4% 감소시킬 수 있고, 샤프비율을 10% 이상 증가시킬 수 있다.
- 비지도 학습 방법을 기반으로 한 팩터가 가장 우수한 성과를 보였다.
- SFC, DFC, DBC의 경우 DEC를 제외하고는 오토인코더가 가장 낮은 표준편차를 나타내며, DEC에서는 특별하게 SPLS가 가장 낮은 표준편차를 기록했다.
- 전반적으로 가장 성능이 좋은 포트폴리오는 DEC 또는 DBC 기반 포트폴리오이며, SFC 및 DFC 기반 포트폴리오도 유사한 성능을 보인다.
4.3. Properties of portfolio weights
이 섹션에서는 공분산 행렬이 바뀜에 따라 포트폴리오 가중치 구조가 어떻게 변하는지 살펴본다.
비교에 사용되는 지표들은 다음과 같다.
- minimum non-zero weight(MIN)
- maximum weight(MAX)
- standard deviation of the portfolio weights(SD)
- portfolio turnover(TO)
- Herfindahl-Hirschman index(HHI)를 활용한 concentration of the portfolio
- percentage of non-zero weigfhts(NZ)
※ Herfindahl-Hirschman index(HHI)
$\sum_{i=1}^N \hat w_i^2$
즉 낮은 HHI 값은 보다 분산된 포트폴리오를 의미한다.
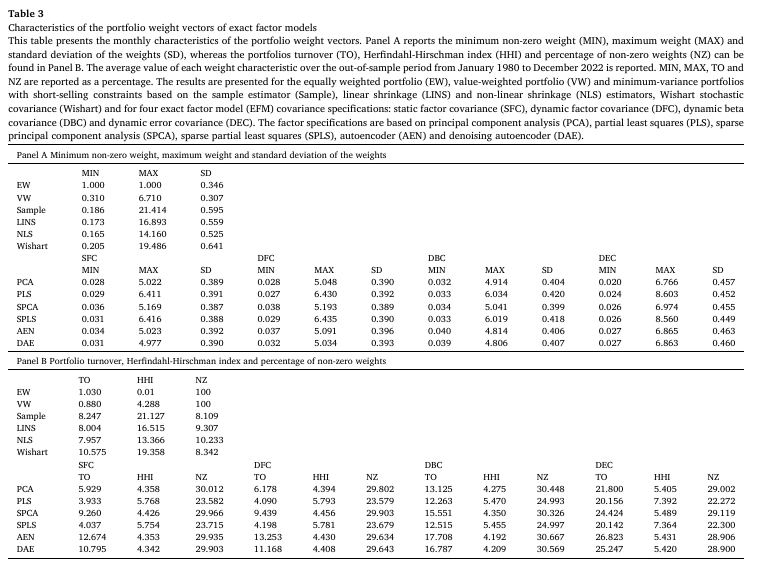
Table 3은 OOS 기간 동안 각 가중치 특성의 평균값을 나타낸다.
- 전반적으로 latent factor 기반 포트폴리오의 경우 더 잘 분산되어 있으며, 다른 벤치마크보다 더 작고 변동성이 작은 가중치를 생성하는 경향이 있다.
- SFC 또는 DFC 기반 포트폴리오가 가장 낮은 가중치 표준편차를 나타낸다.
- turnover의 경우 가장 낮은 값을 가지는 포트폴리오는 SFC 기반의 PLS 및 SPLS 모델이며, DBC 및 DEC, 그리고 오토인코더 모델은 다른 모델보다 더 높은 turnover 값을 가진다.
- HHI 및 non-zero weights 비율에 따르면 비지도 학습 기반 latent factor model이 다른 모델보다 잘 분산되어 있다는 것을 알 수 있다.
4.4. Portfolio performance after transaction costs
포트폴리오 수익률의 경우 회전율을 기반으로 거래 비용을 고려해야 하기 때문에 거래 비용 수준을 c로 가정하여 전체 포트폴리오의 거래 비용을 다음과 같이 나타낸다.
$c \Vert ω_{t+1} - ω_t\Vert_1$
따라서 거래 비용을 고려한 포트폴리오 수익률은 다음과 같이 나타난다.
$r_{p,t+1}^{TC} = (1 + r_{p,t+1})(1 - c \Vert ω_{t+1} - ω_t\Vert_1) - 1$
본 연구에서는 거래 비용 c = 5bps, 20bps 로 가정하여 각각 분석하였다.
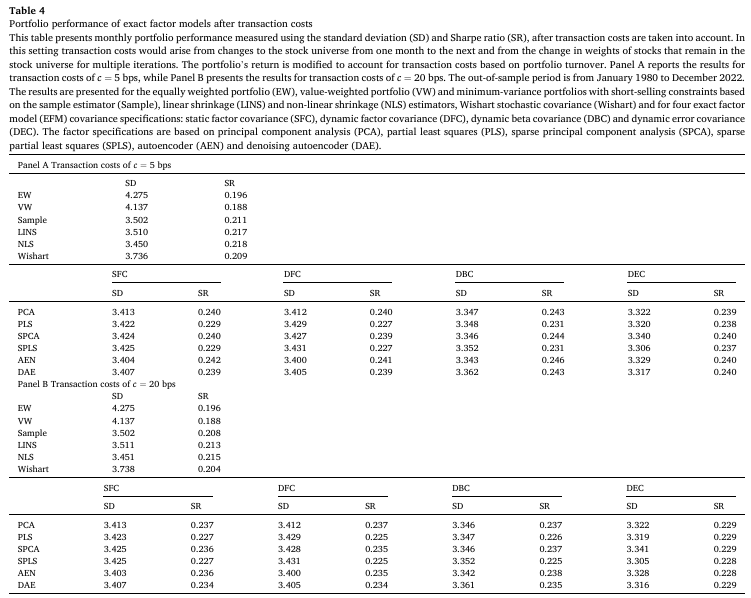
Table 4는 거래 비용을 반영한 포트폴리오 성과를 나타낸 표이다.
- 포트폴리오 표준편차의 경우 거래비용을 반영해도 성과의 차이가 크게 나지 않는다.
- 샤프 비율 측면에서, EW 및 VW 대비 초과 성과는 여전히 의미가 있긴 했지만 거래비용이 반영되면서 이 차이가 감소했다.
- 가장 큰 영향을 받은 전략은 Wishart, 비선형 팩터 기반 모델, DBC 및 DEC 기반 모델(turnover가 높았던 모델)들로 나타났다.
4.5. Statistical significance of portfolio performance
본 논문에서는 추가적으로 두 포트폴리오의 성과가 통계적으로 유의미한지 검증하기 위해 Ledoit and Wolf(2011)의 standard deviation test 및 Opdyke(2007)의 sharpe ratio test를 진행한다.
- Ledoit and Wolf(2011) 귀무가설: “두 포트폴리오의 표준편차가 동일하다.”
- Opdyke(2007) 귀무가설: “두 포트폴리오의 샤프 비율이 동일하다.”
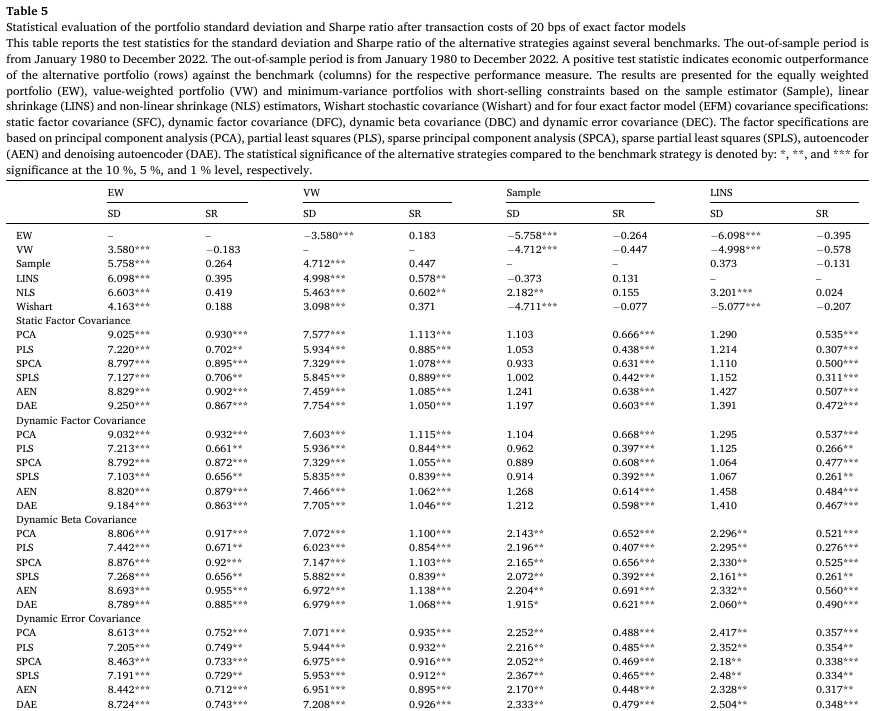
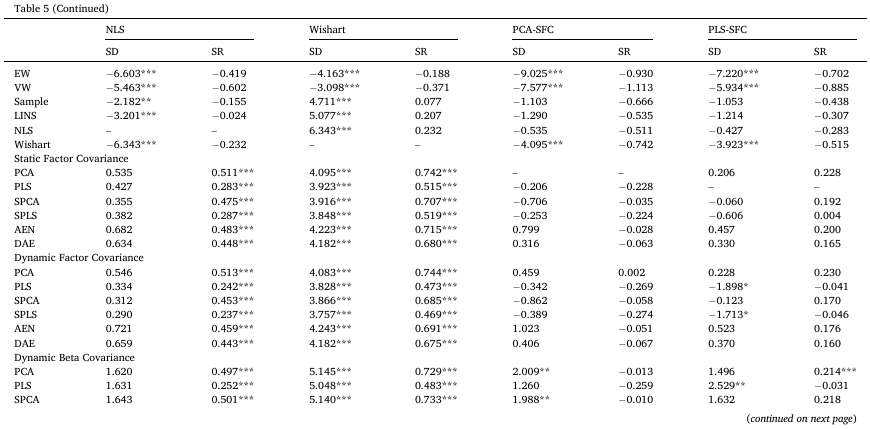
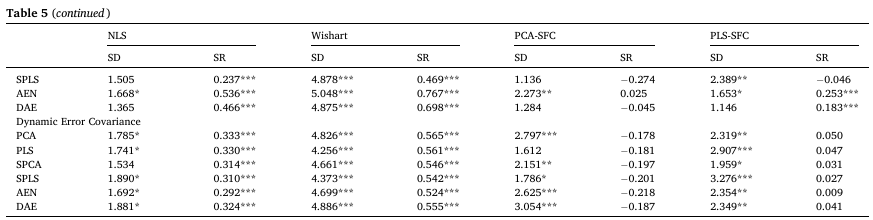
Table 5는 거래비용 20bps를 고려한 포트폴리오 수익률을 기반으로 검정을 진행한 결과를 나타낸다. 양수 test-statistic은 해당 측정치에 대한 경제적 초과 성과를 나타내며, 6개의 벤치마크 이외에도 SFC-PCA 및 SFC-PLS를 벤치마크로 사용하였다.
- 팩터모델 기반 포트폴리오는 거래비용 반영 이후 다른 벤치마크 대비 통계적으로 유의한 초과 성과를 보인다.
- 표준편차의 경우 EW 대비 모든 전략에서 1% 수준에 대해 유의함을 보이지만, 샤프 비율의 경우 팩터 모델 기반 전략에서만 유의함을 보인다.
- VW 대비 결과 또한 EW를 제외한 모든 전략이 1% 수준에서 유의한 초과 성과를 보이며, 샤프 비율의 경우 모든 팩터 모델 기반 전략이 5% 수준에서 유의한 초과 성과를 보인다.
- Sample 및 shrinkage estimator 벤치마크 대비 결과는 표준편차 측면에서 SFC 기반 모델들이, 특히 NLS와 비교할 경우 대부분의 팩터 모델 기반 전략이 유의한 초과 성과를 거두지 못했지만, 샤프 비율 측면에서는 5% 수준에서 팩터 모델 기반 전략들이 모두 유의한 초과 성과를 보였다.
- SFC-PCA 및 SFC-PLS를 벤치마크로 할 경우 유의미한 표준편차 초과 성과를 보이는 전략은 DBC 및 DEC 기반 전략 중 일부였다.
4.6. Subperiod analysis
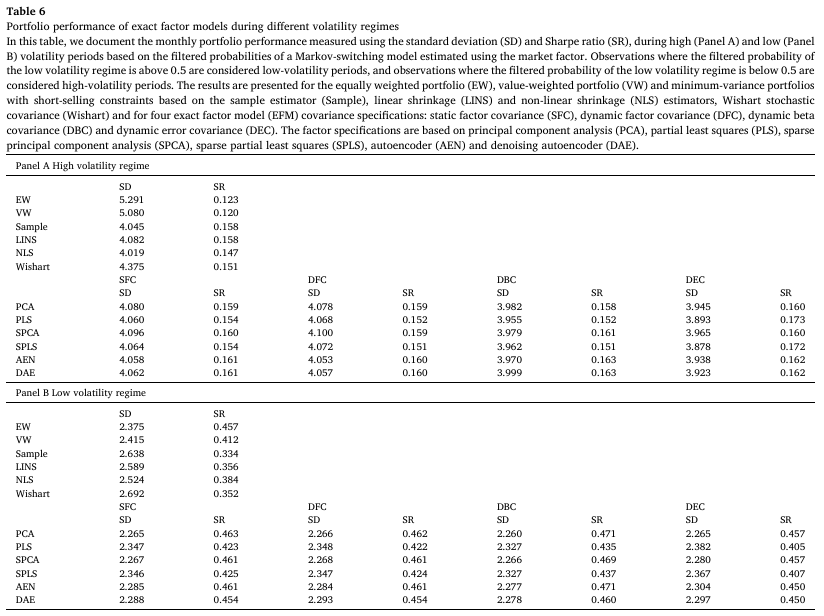
Table 9는 시장 변동성을 기준으로 나누어진 하위 기간에 대한 포트폴리오 성과를 비교한다.
- 패널 A는 높은 변동성 기간에 대한 분석 결과이며, 모든 optimal portfolio가 EW 및 VW 대비 성과가 우수함을 보인다.
- DBC 및 DEC 기반 전략의 경우 다른 전략보다 더 낮은 위험과 더 높은 샤프 비율을 보인다.
- 가장 우수한 성과를 보이는 전략은 DEC-PLS 및 DEC-SPLS로, 각각 월간 샤프 비율이 0.173, 0.172를 나타낸다.
- 패널 B는 낮은 변동성 기간에 대한 분석 결과이며, latent factor model 기반 전략들이 EW와 유사한 성과를 보이며, 다른 벤치마크보다는 더 우수한 성과를 보인다.
4.7. Varying number of assets
추가적으로 이 절에서는 포트폴리오의 자산 수가 성과에 얼만큼 영향을 미치는지 분석한다.
기존에는 N = 100 으로 설정했지만, 추가로 시가총액 상위 N = {30, 50, 200, 300, 400, 500} 에 대해 분석하며, 벤치마크 및 SFC 기반 전략의 포트폴리오 결과는 다음과 같다.
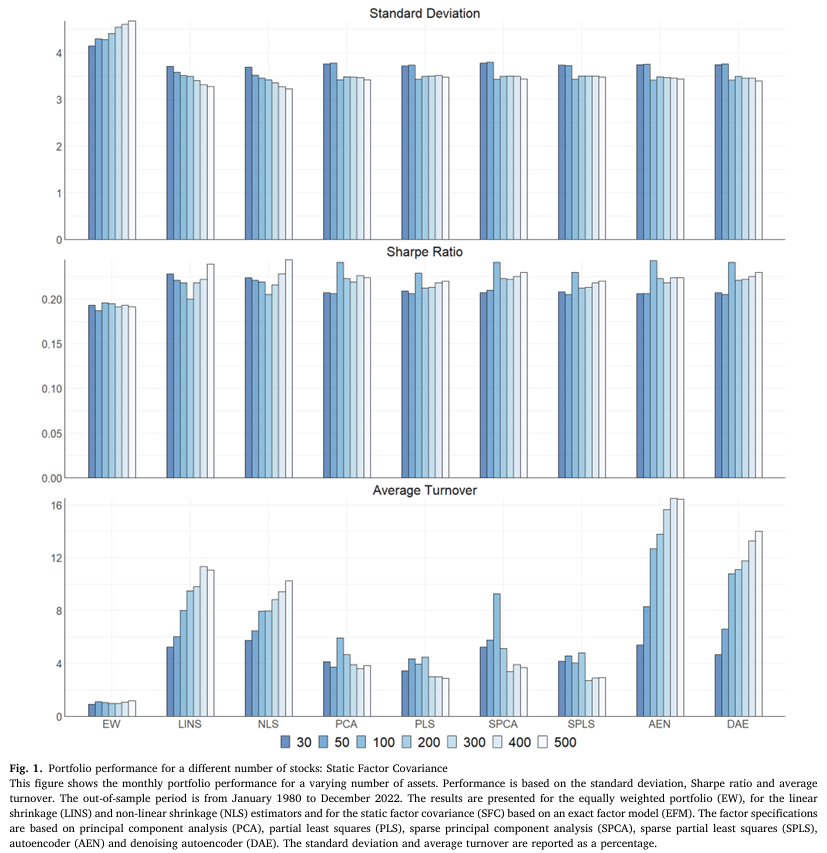
- 자산 수가 변해도 EW 포트폴리오는 여전히 다른 전략들에 비해 저조한 성과를 보이며, 자산 수가 증가할수록 표준편차가 증가하는 경향을 보인다.
- 자산 수 N = {30, 50} 으로 설정하면 shrinkage estimator 기반 전략이 latent factor model 기반 전략보다 두 지표 모두 우수한 성과를 보인다.
- latent factor model 기반 전략은 N = {30, 50} 일 때 변동성이 높지만 이후부터는 안정적인 변동성을 보인다.
- 평균 월간 turnover의 경우 shrinkage estimator 기반 전략 및 SFC-AEN, SFC-DAE는 자산 수가 증가함에 따라 계속 증가하는 경향을 보인다.
- SFC 기반 latent factor model 중에서는 AEN 및 DAE가 가장 높은 turnover를 보이며 PCA, PLS, SPLS가 전반적으로 가장 낮은 turnover를 보였다.
4.8. Performance of approximate factor models
이 절에서는 지금까지 진행했던 exact factor models(잔차 공분산 행렬이 대각행렬인 형태) 이외에 approximate factor models(AFM)를 추가로 고려한다.
잔차 공분산 행렬이 정적이었던 SFC, DFC, DBC에서는 잔차 공분산을 Ledoit and Wolf(2004)의 linear shrinkage estimator를 사용하여 추정하며, 동적 잔차 공분산 형태인 DEC에서는 Engle, Ledoit and Wolf(2019)의 DCC-NL 동적 공분산 추정기를 활용하여 추정한다.
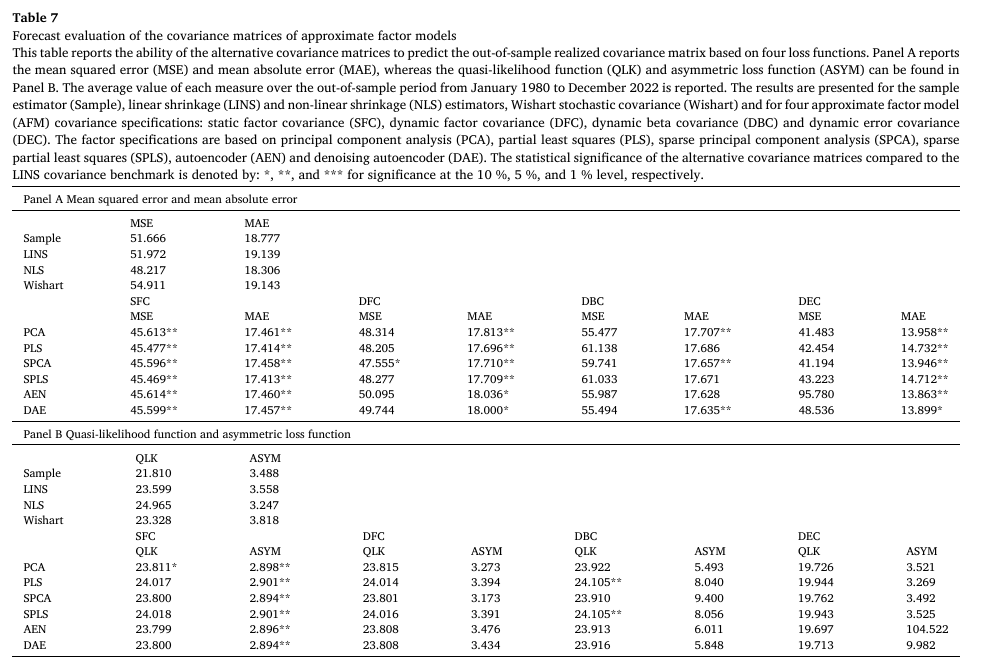
Table 7은 approximate factor models에서의 결과를 나타낸다.
- 기존의 exact factor models과 비교하면 MSE, MAE, ASYM 측면에서 latent factor model의 공분산 예측력이 약화된 것을 확인할 수 있다.
- QLK 손실 측면에서는 일부 개선이 있긴 하지만, LINS 벤치마크에 비교했을 때 유의미한 초과 성과를 거두지 못한다.
- SFC 기반 전략들은 MSE 및 MAE 측면에서 벤치마크를 유의미하게 능가하지만, 동적 기반 전략(DFC, DBC, DEC)들은 주로 MAE에서만 유의미한 초과 성과를 보인다.
- QLK 및 ASYM 측면에서도 SFC 기반 전략들은 유의미한 ASYM 초과 성과를 보이는 반면 동적 기반 전략들은 QLK에서만 벤치마크 대비 낮은 값을 가지며, 통계적으로도 유의미하지 않다.
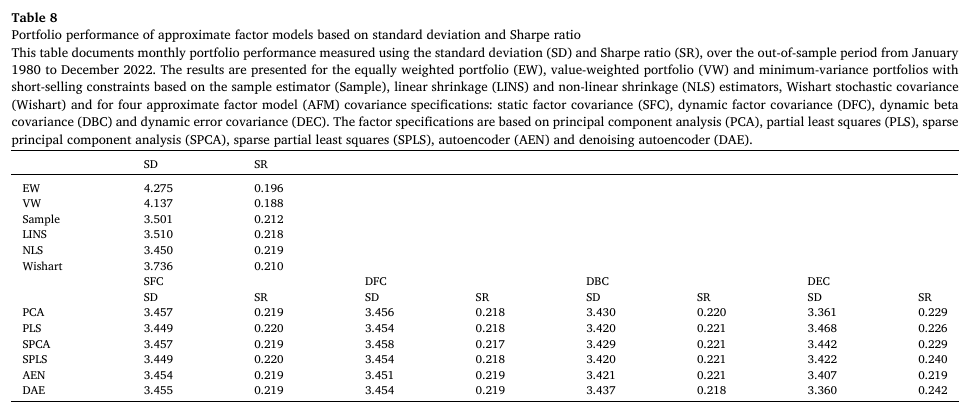
Table 8에서는 표준편차와 샤프비율 측면에서 approximate factor models 기반 latent factor model의 경제적 가치를 비교한다.
- 전반적으로 latent factor model은 exact factor models 기반이 approximate factor models 기반 보다 일관되게 우수한 결과를 보인다.
- 팩터 모델 전략들은 여전히 EW 및 VW 벤치마크를 능가하지만 이러한 성과는 다른 벤치마크와 비교했을 때 차이는 점점 줄어드는 경향을 보인다.
5. Conclusion
본 논문에서는 최소-분산 포트폴리오의 한계점인 공분산 행렬 품질 의존 문제를 해결하고자 자산 공분산 행렬 구조에 latent factor model을 적용한 다양한 방법을 비교했다.
- sparse factor model 뿐만 아니라 비선형성을 도입한 autoencoder factor model 등과 같은 다양한 팩터 모델
- 정적 팩터 모델(SFC) 뿐만 아니라 동적 팩터 모델(DFC), 동적 베타 팩터 모델(DBC), 동적 잔차 공분산 팩터 모델(DEC) 기반 latent factor model
결과적으로, 2가지 대칭 손실함수(MSE. MAE)에 기반한 예측 정확도 결과는 대부분의 팩터 모델이 다른 벤치마크보다 우수한 성과를 보이며, 2가지 비대칭 손실함수(QLK, ASYM)에 따르면 팩터 모델의 향상된 성과를 과대 예측이 감소한 것에 기인한다는 것을 알 수 있게 해준다.
추가적으로 각 방식으로 추정된 공분산을 GMV에 넣고 포트폴리오 성과를 비교한 결과 또한 팩터 모델 전략들이 더 높은 샤프비율 및 더 낮은 포트폴리오 변동성을 가진다는 것을 확인할 수 있다.
특히 팩터 모델 기반 GMV 포트폴리오의 경우 다른 벤치마크에 비해 전반적으로 낮은 turnover를 나타냈으며, 가중치 변동이 적으며 더 잘 분산된 포트폴리오를 제공한다.
마지막으로 본 논문에서는 이후 발전 방향으로 2-stage가 아닌 E2E 방식으로 추정된 팩터 모델 기반 공분산 행렬 추정 방식과, latent factor를 구성하는 과정에서 단순히 자산 수익률만이 아닌 다른 특성값들을 활용할 수 있다는 점, 개별 주식이 아닌 다양한 자산군에 대한 분석으로 확장할 수 있음을 언급한다.
리뷰를 마치며
현재 진행중인 연구의 key paper가 되는 만큼 정말 흥미롭게 읽은 논문으로, 팩터모델 기반 공분산 추정 방법을 정말 다양하게 비교한 좋은 논문인 것 같다.
특히 팩터 모델 구성 방법 뿐만 아니라 정적 팩터 모델과 동적 팩터 모델을 분류한 점, exact factor model과 approximate factor model 모두 진행한 점에서 굉장히 꼼꼼하게 분석을 진행했다고 느꼈다. 또한 이 글에서는 Internet Appendix에 대해 리뷰하지 않았지만, Internet Appendix에서 거래비용을 반영하여 턴오버를 고려하여 목적함수를 설계한 GMV, short selling을 허용한 GMV에 대한 결과를 비교하기도 했다.
개인적으로 아쉬웠던 점은 왜 observable factor model이 아닌 unobservable factor model으로 했는지에 대한 언급이 없었다는 점과, 팩터모델의 공분산 추정능력 및 포트폴리오 성과에 초점을 맞춘 만큼 각 팩터 모델에서의 latent factor의 특성을 비교한 것은 없었다는 점이었다.
실제로 Internet Appendix에서 각 팩터모델의 train 하이퍼파라미터에 factor 개수를 1~5로 설정했다고 언급되어 있는데, 각 모델마다 latent factor의 개수가 몇 개가 최적이었는지, 왜 그런 결과가 나온 것인지에 대한 언급이 있었으면 더 좋았을 것 같다.
나 또한 이 논문의 Conclusion에서 언급된 E2E 기반 팩터모델에 대해 연구하고 있는데, 현재는 observable factor model을 먼저 연구하고 있지만 후에 latent factor model까지 확장하면 좋을 것 같다고 생각했다.
특히 latent factor model은 factor loading 뿐만 아니라 latent factor 자체도 E2E로 학습시킬 수 있기 때문에 Decision-Focused Learning을 적용하는 것이 매우 재미있는 주제가 될 것 같다.