파이썬으로 구현하는 로보어드바이저 chapter 3. 평균-분산 전략 구현 및 시뮬레이션 분석
Chapter 3. 평균-분산 전략 구현 및 시뮬레이션 분석
MVO를 기반으로 한 투자전략을 시뮬레이션하기 위한 전체 과정은 다음과 같다.
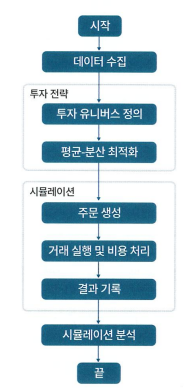
시뮬레이션에 있어서 다음과 같은 시장 환경을 가정한다.
- 모든 주문은 다음 거래일의 시작 가격으로 체결된다.
- 거래 시 수수료와 슬리피지를 고려하지만 세금은 무시한다.
3.1.1 데이터 수집
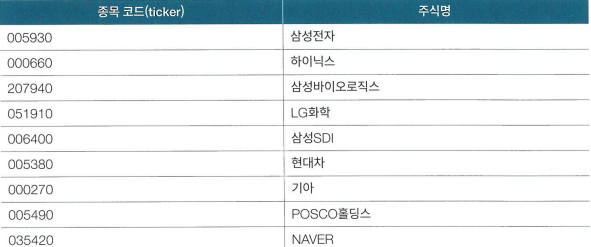
사용할 유니버스는 KOSPI 대표 종목 9가지로 구성한다. 시뮬레이션 기간은 2020년 7월 10일~2023년 9월 27일로 설정한다.
1
from pykrx import stock
주가 데이터를 불러오기 위해 PyKrx라는 파이썬 라이브러리를 사용한다.
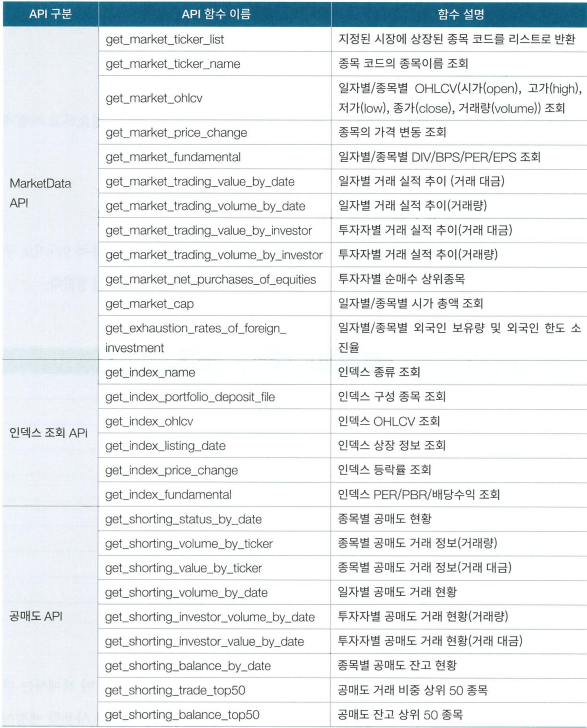
Stock 모듈의 get_market_ohlcv()함수는 주가 조회를 위한 함수로 이때 주가는 OHLCV 형식으로 조회 가능하다. 파라미터는 date, market이며 market의 기본값은 KOSPI이다. 이외의 파라미터는 아래와 같다.

1
2
3
4
5
6
7
import time
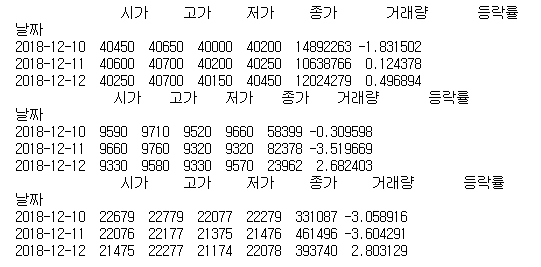
ticker_list = ['005930', '000020', '035720']
for ticker in ticker_list:
df = stock.get_market_ohlcv('20181210', '20181212', ticker)
print(df.head())
time.sleep(1)
3.1.2 평균-분산 최적화

※ 위험 회피 지수 A를 시장 평균적인 값으로 설정한다면 MVO의 목적함수에 효용함수 대신 샤프비율이 들어가도 동일한 결과가 나온다.
→ 효용함수를 최대화하는 MVO는 모두 efficient frontier 위에 위치하게 된다. 이때 CML을 추가하면 efficient frontier와의 접하기 위해 기울기를 최대화하는데 이 기울기가 샤프비율과 동일하다. 따라서 샤프비율을 목적함수로 설정하면 최적의 시장 포트폴리오가 결과값으로 도출된다.
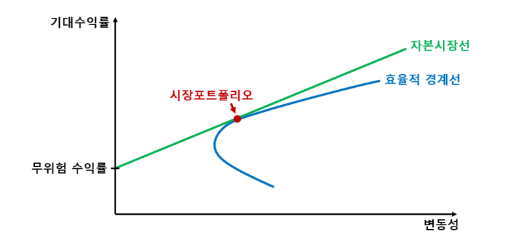
Quant Daddy 블로그
※ 단계
- 자산별 수익률 계산
- 평균분산 모델 파라미터 추정 및 최적화
1
2
3
4
5
6
def calculate_return(ohlcv_data: pd.DataFrame):
close_data = ohlcv_data[['close', 'ticker']].reset_index().set_index(['ticker', 'date'])
close_data = close_data.unstack(level=0)
close_data = close_data['close']
return_data = close_data.pct_change(1) * 100
return return_data
→ 주가 데이터를 받아서 수익률을 계산
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
from typing import Optional, Dict
def get_mean_variance_weights(return_data: pd.DataFrame, risk_aversion: int) -> Optional[Dict]:
# 수익률 계산
expected_return = return_data.mean(skipna=False).to_list()
# 공분산 행렬 계산
cov = return_data.cov(min_periods=len(return_data))
# 공분산 행렬이 비어있거나 결측값이 있으면 None 반환
if cov.isnull().values.any() or cov.empty:
return None
# 평균-분산 최적화
ef = EfficientFrontier(
expected_returns=expected_return,
cov_matrix=cov,
solver='OSQP'
)
# 위험 회피 성향 반영한 최대 효용 함수 계산
ef.max_quadratic_utilty(risk_aversion=risk_aversion)
# 최적화된 포트폴리오 가중치 얻기
weights = dict(ef.clean_weights(rounding=None))
return weights
→ 수익률 데이터와 위험 회피 계수를 입력 파라미터로 받아 투자 포트폴리오의 자산 편입 비중 반환.
3.1.3 거래 흐름 모델링
시뮬레이션에 있어서 중요한 것은 현실과 가깝게 환경을 모델링하고 거래 과정을 재현하는 것.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
# 시장가 주문, 지정가 주문, 정지 시장가 주문, 정지 지정가 주문
class OrderType(Enum):
MARKET = 1
LIMIT = 2
STOPMARKET = 3
STOPLIMIT = 4
# 미쳬결(부분 체결), 완료, 취소
class OrderStatus(Enum):
OPEN = 1
FILLED = 2
CANCELLED = 3
# 매도, 매수
class OrderDirection(Enum):
BUY = 1
SELL = -1
- 주문
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
class Order(object): def __init__(self, dt: datetime.date, ticker: str, amount: int, type: Optional[OrderType] = OrderType.MARKET, limit: Optional[float] = None, stop: Optional[float] = None, id: Optional[str] = None) -> None: self.id = id if id is not None else uuid.uuid4().hex self.dt = dt self.ticker = ticker self.amount = abs(amount) self.direction = OrderDirection.BUY if amount > 0 else OrderDirection.SELL self.type = type self.limit = limit self.stop = stop self.status = OrderStatus.OPEN self.open_amount: int = self.amount
- 거래
※ Assumption- 수수료는 거래금액의 일정 비율로 계산된다.
- 세금과 기타 비용은 고려하지 않는다.
1 2 3 4 5 6 7 8 9 10 11 12 13 14
class Transaction(object): def __init__(self, id: str, dt: datetime.date, ticker: str, amount: int, price: float, direction: OrderDirection, commission_rate: float = config.commission_rate) -> None: self.id = id self.dt = dt self.ticker = ticker self.amount = amount self.price = price self.direction = direction self.commission_rate = commission_rate self.commission = (self.amount * self.price) * self.commission_rate self.settlement_value = -self.direction.value * (self.amount * self.price) - self.commission
- 중개인
※ Assumption- 투자자에게 불리한 슬리피지만 존재한다.
- 주문 체결량은 총거래량의 최대 10%를 넘지 않는다.
- 슬리피지는 가격의 일정 비율로 발생한다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
# 중개인 클래스
class Broker(object):
def __init__(self, slippage_rate: float = config.slippage_rate,
volume_limit_rate: float = config.volume_limit_rate):
self.slippage_rate = slippage_rate
self.volume_limit_rate = volume_limit_rate
# 슬리피지 계산
def calculate_slippage(self, data: Dict, order: Order) -> Tuple[float, int]:
# 슬리피지를 포함한 거래 가격 계산
price = data['open']
simulated_impact = price * self.slippage_rate
if order.direction == OrderDirection.BUY:
impacted_price = price + simulated_impact
else:
impacted_price = price - simulated_impact
# 거래가 가능한 수량 계산
volume = data['volume']
max_volume = volume * self.volume_limit_rate
shares_to_fill = min(order.open_amount, max_volume)
return impacted_price, shares_to_fill
# 주문 처리
def process_order(self, dt: datetime.date, data: pd.DataFrame,
orders: Optional[List[Order]] = None) -> List[Transaction]:
if orders is None:
return []
# 가격 데이터를 딕셔너리로 변환
data = data.set_index('ticker').to_dict(orient='index')
transactions = []
for order in orders:
if order.status == OrderStatus.OPEN:
assert order.ticker in data.keys()
# 슬리피지 계산
price, amount = self.calculate_slippage(
data=data[order.ticker],
order=order
)
if amount != 0:
# 거래 객체 생성
transaction = Transaction(
id=order.id,
dt=dt,
ticker=order.ticker,
amount=amount,
price=price,
direction=order.direction,
)
transactions.append(transaction)
# 거래 객체의 상태와 미체결 수량 업데이트
order.status = OrderStatus.FILLED
order.open_amount -= transaction.amount
return transactions
자산 포지션
```python class AssetPosition(object): def init(self, ticker: str, position: int, latest_price: float, cost: float): self.ticker = ticker self.position = position self.latest_price = latest_price self.cost = cost1
self.total_settlement_value = (-1.0) * self.position * self.cost
def update(self, transaction: Transaction): self.total_settlement_value += transaction.settlement_value self.position += transaction.direction.value * transaction.amount self.cost = (-1.0) * self.total_settlement_value / self.position
if self.position != 0 else 0.0
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
5. 계좌
```python
class Account(object):
def __init__(self, initial_cash: float) -> None:
self.initial_cash = initial_cash
self.current_cash = initial_cash
self.dt = None
self.portfolio: Dict[str, AssetPosition] = {}
self.orders: List[Order] = []
self.transaction_history: List[Dict] = []
self.portfolio_history: List[Dict] = []
self.account_history: List[Dict] = []
self.order_history: List[Dict] = []
self.weight_history: List[Dict] = []
@property
def total_asset(self) -> float:
# 현재 총 자산 계산
market_value = 0
for asset_position in self.portfolio.values():
market_value += asset_position.latest_price * asset_position.position
return market_value + self.current_cash
5-1 자산 포지션 업데이트
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
def update_position(self, transactions: List[Transaction]):
for tran in transactions:
asset_exists = tran.ticker in self.portfolio.keys()
if asset_exists:
# 기존에 보유 중인 자산 포지션 업데이트
self.portfolio[tran.ticker].update(transaction=tran)
else:
# 처음 보유하는 자산 추가
new_position = AssetPosition(
ticker=tran.ticker, position=tran.direction.value * tran.amount,
latest_price=tran.price,
cost=abs(tran.settlement_value) / tran.amount
)
self.portfolio[tran.ticker] = new_position
# 현재 현금 업데이트
self.current_cash += tran.settlement_value
# 거래 히스토리 업데이트
self.transaction_history.append(vars(tran))
5-2 투자 포트폴리오 업데이트
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
def update_portfolio(self, dt: datetime.date, data: pd.DataFrame):
# 가격 데이터를 딕셔너리로 변환
data = data.set_index('ticker').to_dict(orient='index')
# 자산의 최신 가격 업데이트
for asset_position in self.portfolio.values():
assert asset_position.ticker in data.keys()
asset_position.latest_price = data[asset_position.ticker]['close']
# 투자 포트폴리오 히스토리 업데이트 (현금과 자산)
self.portfolio_history.append(
{'date': dt, 'ticker': 'cash', 'latest_price': self.current_cash})
self.portfolio_history.extend(
[{'date': dt} | vars(asset_position)
for asset_position in self.portfolio.values()])
# 장부 금액 히스토리 업데이트
self.account_history.append(
{'date': dt, 'current_cash': self.current_cash,
'total_asset': self.total_asset})
5-3 주문 업데이트
1
2
3
4
5
6
7
8
9
10
11
def update_order(self):
# 완료 상태의 주문
filled_orders = [order for order in self.orders
if order.status == OrderStatus.FILLED]
# 주문 히스토리 업데이트
self.order_history.extend([vars(order) for order in filled_orders])
# 미완료 상태의 주문은 현재 주문으로 유지
open_orders = [order for order in self.orders
if order.status == OrderStatus.OPEN]
self.orders[:] = open_orders
3.1.4 평균-분산 시뮬레이션
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
def order_target_amount(account: Account, dt: datetime.date,
ticker: str, target_amount: int) -> Optional[Order]:
# 투자 포트폴리오의 각 자산 및 보유 수량
positions = {asset_position.ticker: asset_position.position
for asset_position in account.portfolio.values()}
# 자산의 보유 수량
position = positions.get(ticker, 0)
# 거래 수량 계산
amount = target_amount - position
if amount != 0:
# 주문 객체 생성
return Order(dt=dt, ticker=ticker, amount=amount)
else:
return None
→ 보유 수량과 목표 수량의 차이가 있으면 주문을 생성하고 없으면 None을 반환한다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
def calculate_target_amount(account: Account, ticker: str,
target_percent: float, data: pd.DataFrame) -> int:
assert ticker in data['ticker'].to_list()
# 총 자산
total_asset = account.total_asset
# 자산의 현재 가격
price = data.loc[data['ticker'] == ticker, 'close'].squeeze()
# 목표 보유 수량 계산
target_amount = int(np.fix(total_asset * target_percent / price))
return target_amount
→ 목표 편입 비중을 목표 수량으로 변환하는 역할을 한다.
총자산에 자산의 목표 편입 비중을 곱해서 목표 자산을 계산하고, 목표 자산을 현재 가격으로 나눠서 목표 수량을 계산한다.
1
2
3
4
5
6
7
8
9
def order_target_percent(account: Account, dt: datetime.date, ticker: str,
target_percent: float, data: pd.DataFrame) -> Optional[Order]:
# 목표 보유 수량 계산
target_amount = calculate_target_amount(account=account, ticker=ticker,
target_percent=target_percent, data=data)
# 목표 수량에 따라 주문
return order_target_amount(account=account, dt=dt, ticker=ticker,
target_amount=target_amount)
→ 목표 수량에 맞게 주문
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
def rebalance(dt: datetime.date, data: pd.DataFrame, account: Account, weights: Dict):
# 포트폴리오에서 더 이상 포함되지 않는 자산은 매도
for asset_position in account.portfolio.values():
if asset_position.ticker not in weights.keys():
order = order_target_percent(account=account, dt=dt,
ticker=asset_position.ticker,
target_percent=0.0, data=data)
# 주문 목록에 생성된 주문 추가
if order is not None:
account.orders.append(order)
# 자산을 목표 편입 비중으로 조정
for ticker, target_percent in weights.items():
order = order_target_percent(account=account, dt=dt,
ticker=ticker,
target_percent=target_percent, data=data)
# 주문 목록에 생성된 주문 추가
if order is not None:
account.orders.append(order)
→ 포트폴리오 리밸런싱 과정. 목표 투자 포트폴리오에 포함되지 않을 자산은 매도, 나머지 자산은 목표 편입 비중으로 조정한다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
def simulate_mean_variance(ohlcv_data: pd.DataFrame, look_back: int):
account = Account(initial_cash=100000000)
broker = Broker()
# 수익률 계산
return_data = calculate_return(ohlcv_data=ohlcv_data)
for date, ohlcv in ohlcv_data.groupby(['date']):
print(date.date())
# 주문 처리 및 거래 생성
transactions = broker.process_order(dt=date, data=ohlcv, orders=account.orders)
# 계좌 내 자산 포지션, 투자 포트폴리오, 주문 업데이트
account.update_position(transactions=transactions)
account.update_portfolio(dt=date, data=ohlcv)
account.update_order()
# 현재 날짜의 수익률 데이터
return_data_slice = return_data.loc[:date].iloc[-look_back:]
# 자산 편입 비중 계산 및 뒤처리
weights = get_mean_variance_weights(return_data=return_data_slice, risk_aversion=3)
rounded_weights = (None if weights is None else
{k: round(v, 3) for k, v in weights.items()})
print(f'Portfolio: {rounded_weights}')
if weights is None:
continue
# 투자 포트폴리오 조정
rebalance(dt=date, data=ohlcv, account=account, weights=weights)
return account
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
def get_lookback_fromdate(fromdate: str, lookback: int, freq: str) -> str:
# freq에 따라 룩백 기간 포함된 예상 시작 날짜를 설정
if freq == 'd':
estimated_start_date = '1990-01-01'
elif freq == 'm':
estimated_start_date = (pd.to_datetime(fromdate) - pd.DateOffset(months=lookback))
elif freq == 'y':
estimated_start_date = (pd.to_datetime(fromdate) - pd.DateOffset(years=lookback))
else:
raise ValueError
# 설정 기간(estimated_start_date ~ fromdate)의 KOSPI 데이터를 다운로드
kospi = stock.get_index_ohlcv(fromdate=str(estimated_start_date.date()),
todate=fromdate, ticker='1001', freq=freq)
# 룩백 기간을 포함하는 정확한 시작 날짜를 반환
return str(kospi.index[-lookback].date())
사용자가 지정한 기간에 시뮬레이션을 하기 위해서는 시뮬레이션 시작일에서 과거로 자산 배분 모델의 룩백 기간만큼 이동한 시점에서부터의 데이터가 필요함.
KOSPI 데이터의 날짜를 기준으로 시작 날짜를 룩백 기간만큼 과거 방향으로 이동시킨다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
fromdate = '2020-07-10'
todate = '2023-09-27'
total_look_back = 1 + 24
# 룩백 기간을 포함한 시작 날짜 계산
adj_fromdate = get_lookback_fromdate(fromdate=fromdate,
lookback=total_look_back, freq='m')
# 데이터 로더 설정
data_loader = PykrxDataLoader(fromdate=adj_fromdate,
todate=todate, market='KOSPI')
# 데이터 로드
ohlcv_data = data_loader.load_stock_data(ticker_list=ticker_list,
freq='m', delay=1)
# 평균-분산 전략 시뮬레이션 실행
simulation_account = simulate_mean_variance(ohlcv_data=ohlcv_data,
look_back=24)
→ 시뮬레이션이 진행됨에 따라 매일 최적화된 투자 포트폴리오의 자산 편입 비중이 출력된다.
3.2.1 시뮬레이션 결과 전처리
1
2
3
4
5
6
df_account = pd.DataFrame(simulation_account.account_history).set_index('date')
df_portfolio = pd.DataFrame(simulation_account.portfolio_history).set_index('date')
df_portfolio = df_portfolio.assign(
ticker=df_portfolio['ticker'].apply(lambda x: f'{x}({ticker_to_name(x)})')
)
→ pandas의 DataFrame 형식으로 변환
1
2
3
4
5
def ticker_to_name(ticker: str) -> str:
if ticker == 'cash':
return '현금'
else:
return stock.get_market_ticker_name(ticker=ticker)
→ 종목 코드가 ‘cash’인 경우에는 ‘현금’으로 반환, ‘cash’가 아니라면 종목 코드의 이름을 가져온다.
1
2
analysis_fromdate = df_account.index[total_look_back - 1]
df_portfolio = df_portfolio.loc[analysis_fromdate:]
시뮬레이션 시작일의 룩백 기간에 해당하는 기간의 결과는 정상적인 결과라고 볼 수 없기 때문에 분석 과정에서는 시작 날짜를 계산하고 종료일까지의 결과만 잘라서 분석한다.
1
returns = df_accout['total_asset'].pct_change().loc[analysis_fromdate:]
투자 포트폴리오의 성능 지표 계산을 위해 단기 수익률 계산
1
2
3
4
5
kospi = data_loader.load_index_data(ticker_list=['1001'], freq='m', delay=1)
kospi_returns = kospi['close'].pct_change().loc[analysis_fromdate:]
kospi_returns.iloc[0] = 0.0
kospi_returns.name = 'kospi_return'
kospi_returns.index.name = 'date'
→ 벤치마크 포트폴리오(KOSPI) 월간 수익률 계산
1
2
3
4
5
annualization_factor = {
'd': 252,
'm': 12,
'y': 1
}
→ 거래일을 기준으로 하기 때문에 1년은 252일을 일반적으로 사용한다.
3.2.2 포트폴리오 성능 지표
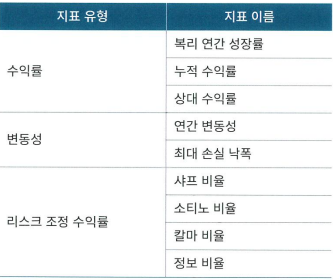
- 연평균 복리 성장률(CAGR)

특정 기간 동안의 연간 성장률을 의미한다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
def cagr(returns: pd.Series, freq: str = 'd') -> float:
if len(returns) < 1:
return np.nan
# 연환산 계수 설정
ann_factor = annualization_factor[freq]
# 총 연수 계산
num_years = len(returns) / ann_factor
# 누적 수익률 계산
cum_return = (returns + 1).prod()
# 연평균 성장률 계산
return cum_return ** (1 / num_years) - 1
- 최대 손실 낙폭(MDD)
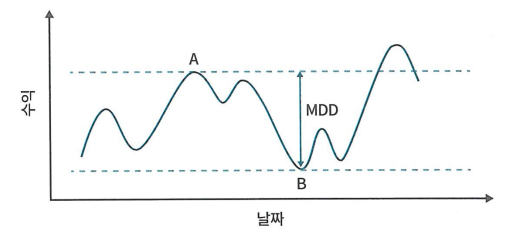
1
2
3
4
5
6
7
8
9
10
11
12
13
14
def mdd(returns: pd.Series) -> float:
if len(returns) < 1:
return np.nan
# 누적 수익률 계산
cum_returns = (returns + 1).cumprod()
# 각 시점까지의 최대 누적 수익률 계산
max_return = np.fmax.accumulate(cum_returns, axis=0)
# 최대 낙폭(MDD) 계산
mdd = ((cum_returns - max_return) / max_return).min()
return mdd
- 샤프 비율

성과 분석에서 가장 일반적으로 활용되는 지표.
연 환산 인자가 분자에는 a만큼, 분모에는 $\sqrt{a}$ 만큼 곱해진다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
def sharpe_ratio(returns: pd.Series, risk_free: float = 0, freq: str = 'd') -> float:
if len(returns) < 2:
return np.nan
# 조정된 수익률: 수익률에서 무위험 수익률을 차감
adjusted_returns = returns - risk_free
# 연환산 계수 설정
ann_factor = annualization_factor[freq]
# 샤프 비율 계산: 평균 초과 수익률을 표준 편차로 나눈 값
sharpe_ratio = (adjusted_returns.mean() / adjusted_returns.std()) * np.sqrt(ann_factor)
return sharpe_ratio
- 소티노 비율
- 투자자는 하락 변동성을 더 중요하게 생각하지만 샤프비율은 이러한 점을 반영하지 못함.
→ fat tail 성향이 강한 주가 데이터 분포의 경우 표준편차가 하락 변동성을 과소평가할 수 있다.
이러한 점을 해결할 수 있는 지표로 활용

→ ※ 일반적으로 평균 수익률 대신 무위험 수익률을 사용하는 것으로 알고 있음.

1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
def sortino_ratio(returns: pd.Series, risk_free: float = 0, freq: str = 'd') -> float:
if len(returns) < 2:
return np.nan
# 무위험 수익률을 차감한 조정된 수익률
adjusted_returns = returns - risk_free
# 음수 수익률만 추출하여 하락 위험 계산
negative_returns = adjusted_returns[adjusted_returns < 0]
downside_risk = np.sqrt(np.mean(negative_returns.pow(2)))
# 연환산 계수 설정
ann_factor = annualization_factor[freq]
if downside_risk == 0:
return np.nan
# 솔티노 비율 계산
sortino_ratio = (adjusted_returns.mean() / downside_risk) * np.sqrt(ann_factor)
return sortino_ratio
칼마 비율

정보 비율

→ 벤치마크 포트폴리오 대비 성과를 측정하기 위해 활용. $r_f$ → $r_b$
$Tracking \, Error = \sqrt{\frac{1}{n} \sum_{i=1}^{n} \left( R_{p,i} - R_{b,i} \right)^2 }$

3.2.3 시각화를 통한 시뮬레이션 분석
위에서 설명한 성능 지표의 경우 시간 정보와 투자구조를 반영하지 못하는 한계가 존재하기 때문에 이번에는 시각화 기법을 통해 성과 변화를 시간의 흐름에 따라 보여준다.
- 누적 수익률 곡선
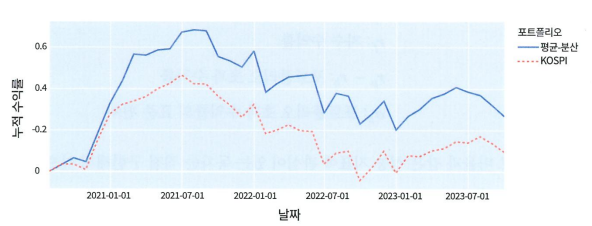
이를 통해 시간의 흐름에 따른 성과를 직관적으로 알 수 있을 뿐만 아니라 변동 추세도 확인 가능하다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
def plot_cumulative_return(returns: pd.Series, benchmark_returns: pd.Series,
strategy_name: str = 'My Strategy',
benchmark_name: str = 'KOSPI') -> None:
# 포트폴리오의 누적 수익률 계산
cum_returns = (returns + 1).cumprod() - 1
# KOSPI의 누적 수익률 계산
benchmark_cum_returns = (benchmark_returns + 1).cumprod() - 1
# 그래프 객체 생성
fig = go.Figure()
# 포트폴리오의 누적 수익률 곡선
fig.add_trace(go.Scatter(x=cum_returns.index, y=cum_returns, name=strategy_name))
# KOSPI의 누적 수익률 곡선
fig.add_trace(go.Scatter(x=benchmark_cum_returns.index, y=benchmark_cum_returns,
name=benchmark_name, line = dict(dash='dot')))
# 날짜 표시 형식
fig.update_xaxes(tickformat='%Y-%m-%d')
# 그래프 설정
fig.update_layout(
width=800,
height=400,
xaxis_title='날짜',
yaxis_title='누적 수익률',
legend_title_text='포트폴리오',
)
fig.show()
- 단기 수익률 변동 막대그래프
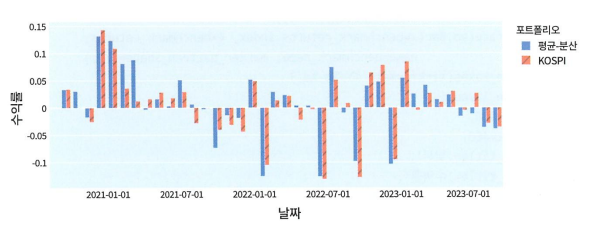
구간별로 각 포트폴리오의 수익률 확인 가능.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
def plot_single_period_return(returns: pd.Series,
benchmark_returns: pd.Series,
strategy_name: str = 'My Strategy',
benchmark_name: str = 'KOSPI') -> None:
fig = go.Figure()
fig.add_trace(go.Bar(x=returns.index, y=returns,
name=strategy_name))
fig.add_trace(go.Bar(x=benchmark_returns.index, y=benchmark_returns,
name=benchmark_name, marker_pattern_shape='/'))
fig.update_xaxes(tickformat='%Y-%m-%d')
fig.update_layout(
width=800,
height=400,
xaxis_title='날짜',
yaxis_title='수익률',
legend_title_text='포트폴리오',
)
fig.show()
- 개별 자산 누적 수익 곡선
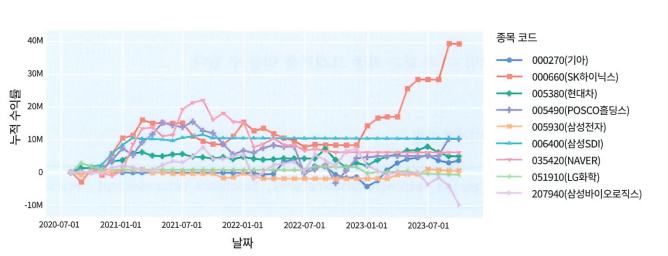
각 자산의 누적 수익률 확인 가능.
포트폴리오 성과에 각 자산이 기여한 정도를 직관적으로 파악할 수 있다.
1
2
3
4
5
6
7
8
9
10
11
12
13
def plot_cumulative_asset_profit(df_portfolio: pd.DataFrame) -> None:
df_portfolio = df_portfolio.assign(
profit=((df_portfolio['latest_price'] - df_portfolio['cost'])
* df_portfolio['position']).fillna(0)
)
df_asset_profit = df_portfolio[['ticker', 'profit']].set_index(
'ticker', append=True).unstack(level=-1, fill_value=0)['profit']
df_asset_position = df_portfolio[['ticker', 'position']].set_index(
'ticker', append=True).unstack(level=-1, fill_value=0)['position']
df_asset_profit_change = df_asset_profit.diff()
df_asset_profit_change[df_asset_position == 0] = 0
df_asset_cumulative_profit = df_asset_profit_change.cumsum()
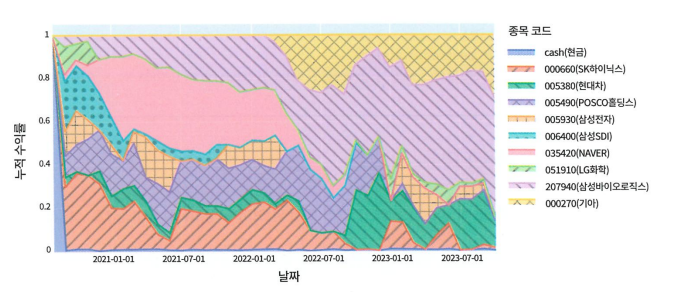
- 자산 편입 비중 영역 차트
포트폴리오에서 각 자산의 크기를 알수 있다.
→ 포트폴리오가 잘 다각화 되었는지 확인할 때 좋은 방법
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
def plot_asset_weight(df_portfolio: pd.DataFrame) -> None:
# 현금의 보유수량을 1로 설정
df_portfolio = df_portfolio.assign(
position=df_portfolio['position'].fillna(1)
)
# 자산의 시가 총액 계산
df_portfolio = df_portfolio.assign(
value=df_portfolio['latest_price'] * df_portfolio['position']
)
# 자산의 편입 비중 계산
df_portfolio = df_portfolio.assign(
weight=df_portfolio['value'].groupby('date').transform(lambda x: x / x.sum())
)
fig = px.area(data_frame=df_portfolio, y='weight',
color='ticker', pattern_shape='ticker')
fig.update_xaxes(tickformat='%Y-%m-%d')
fig.update_layout(
width=800,
height=400,
xaxis_title='날짜',
yaxis_title='자산 편입 비중',
legend_title_text='종목 코드',
)
fig.show()