최적화 스터디: Advances in the Theory of Portfolio Risk Measures
해당 게시글은 SIMULATION AND OPTIMIZATION IN FINANCE 원서를 리뷰한 글입니다.
투자 위험을 나타내는 대표적인 지표가 바로 분산인데, 이는 하방위험과 상승위험을 동일하게 반영한다는 점에서 문제가 있다.
투자자들은 기대를 초과하는 결과보다는 기대에 미치지 못하는 결과에 대해 더 우려하는 경향이 있기 때문에 실제로는 하방 위험에 대해 더 집중적으로 고려되야 한다.
따라서 이번 장에서는 다양한 위험 지표에 대해 소개한다.
8.1 CLASSES OF RISK MEASURES
일반적으로 위험 측정치는 두 가지의 범주로 나눌 수 있는데,
- dispersion
- downside risk
8.1.1 Dispersion Risk Measures
분산 위험 측정치는 포트폴리오의 기대수익률을 중심으로 수익률의 분산 정도를 측정한다.
그러나 이는 긍정적인 편차와 부정적인 편차를 모두 고려하기 때문에 동일한 위험으로 간주한다.
즉, 아무리 초과 성과를 많이 낸 투자전략도 dispersion 값이 높아진다는 것.
Variance and Standard Deviation
마코위츠의 포트폴리오 이론에서부터 사용된 가장 잘 알려진 측정치.
자산 공분산 행렬을 $\sum$, 각 자산의 가중치를 $w$ 라고 할 때, 포트폴리오의 표준편차는 다음과 같다.
$\sigma_p = \sqrt{w’\sum w}$
Absolute Deviation
이 측정치는 포트폴리오의 기대수익률로부터 벗어난 편차의 절댓값의 평균이며, 다음과 같다.
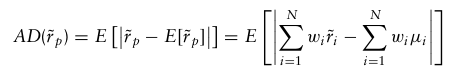
이 측정치를 사용하면 포트폴리오 최적화 문제가 선형이 되기 때문에 선형계획법으로 풀 수 있다는 장점이 존재한다.
또다른 장점은 공분산 행렬을 추정할 필요가 없다는 점인데, 공분산 행렬 추정은 굉장히 어려운 작업이기 때문에 의미가 있다.
추가적으로, 개별 자산 수익률이 다변량 정규분포를 따른다면 AD는 포트폴리오 표준편차의 배수인데,
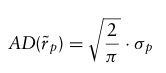
따라서 자산 수익률이 다변량 정규분포를 따르면 MVO의 분산과 AD를 넣은 버전 모두 동일한 결과를 얻을 수 있다.
Absolute Moment
q차 absolute moment 위험 척도는 다음과 같다.
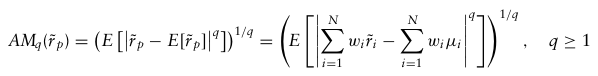
8.1.2 Downside Risk Measures
마코위츠는 투자자가 기대에 미치지 못하는 결과에 대한, 즉 하방 위험을 측정하는 방법으로 semivariance라는 측정치를 제안하는데, 이외에도 lower-partial moment risk 측정치 또는 Fishburn risk 측정치라고 불리는 하방 위험 측정치들이 존재한다.
Lower-Partial Moment
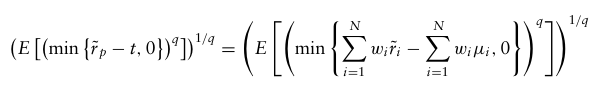
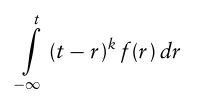
여기서 t는 투자자가 우려하는 하방에 대한 컷오프 지점을 의미하며, 단기 이자율 또는 기대수익률, 최소 요구 수익률로 선택된다.
q가 1일 때는 risk-neutral, 0과 1 사이면 risk-seeking, 1보다 크면 risk-averse 투자자에 해당한다.
Semivariance
semicovariance는 평균 이하의 모든 값의 평균으로부터의 편차의 제곱을 평균한 값으로, k=2이고 t가 포트폴리오 수익의 확률분포의 평균과 같을 때 lower-partial moment risk 측정치와 같다. semicovariance는 다음과 같이 나타낼 수 있다.
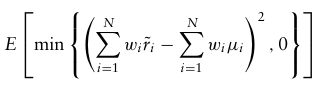
Roy’s Safety-First Criterion
이 이론은 전체 포트폴리오 위험 측면에서 생각하는 것이 아니라 투자자의 원금이 보존되도록 하는 구조이며, 투자자의 수익이 임계값 t보다 작거나 같을 확률을 최소화한다.
$min_w \quad P(\tilde r_p \leq t)$
이는 k=0 일 때 lower-partial moment의 경우가 되며, 이 때의 단기손실 위험을 risk of loss라고 부른다.
Quantile-Based Risk Measures
해당 이론은 분위수를 기반으로 한 위험 척도로, 분포의 분위수 관점에서 변동성을 평가하는 구조이다.
대표적으로 VaR, CVaR이 있으며 CVaR의 경우 k=1 일 때의 lower-partial moment이다.
8.2 VALUE-AT-RISK
VaR은 특정 시간 범위 내에서 지정된 확률 수준에서 예상되는 최대 포트폴리오의 손실을 측정한다. 포트폴리오의 음수 수익률이 γ를 초과할 확률이 ε보다 크지 않도록 하는 값 γ가 나온다.
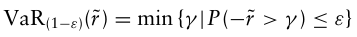
이때 $\tilde r$ 은 벤치마크 대비 초과 수익률이 주로 사용된다.
실무에서는 수익률 분포로 VaR을 정의하지 않고 손익(P/L) 과 같은 데이터 분포로 VaR을 구한다.
손익(P/L)의 경우 양수값은 이익을, 음수값은 손실을 나타내며 100(1-ε)% VaR은 손익 값 분포의 ε번째 백분위수가 된다.
$(P/L){t+1} = V{t+1} + D_{t+1} − V_t$
8.2.2 Calculation of Value-at-Risk for a Normal Distribution
손익(P/L) 데이터가 정규분포를 따른다고 가정하자.
100(1-ε)% VaR을 추정하기 위해 분포의 100(1-ε)번째 백분위 값을 찾아야 한다.
정규분포는 백분위수에 대한 닫힌 형태의 식이 존재하므로 모든 백분위수는 분포의 평균과 표준편차에 대해 나타낼 수 있는데,
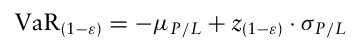
(여기서 z는 표준정규분포 분위수)
다만 VaR은 정규성 가정과 관련된 몇가지 문제가 있다.
정규분포 기반 VaR을 사용하는 것은 정규분포를 따르는 데이터에서는 올바르지만, 대부분의 실제 데이터는 fat tails를 가지는 분포로, 정규분포를 따르지 않는다.
→ 이는 VaR이 실제 VaR을 크게 과소평가하게 될 수 있다.수익률이 정규분포를 따른다고 가정해도, 모델에 대한 입력 매개변수 추정의 부정확성은 위험 평가 작업을 어렵게 만든다.
8.2.3 Calculation of Value-at-Risk Using Historical and Simulated Data Scenarios
VaR을 추정하는 현실적인 방법은 포트폴리오 내의 다양한 자산 가격의 불확실성에 따른 가능한 실현 시나리오를 사용하는 것.
시나리오 접근법은 불확실성 간의 의존성을 암묵적으로 통합하고 실제 백분위를 추정할 수 있게 해준다.
관심 기간 동안 발생 가능한 손익 시나리오가 총 S개 있다면, 100(1-ε)% VaR은 데이터를 오름차순으로 정렬한 뒤 정렬된 배열에서 (S - εS + 1)번째 시나리오를 선택해 구한다.
→ 손실이 그 값보다 더 큰 시나리오의 개수가 εS개를 넘지 않도록 하는 가장 큰 손실 수준을 고르는 것.
VaR 추정을 위한 시나리오 집합을 정하는 기준 중 가장 단순한 방법은 일정한 구간에 대해 과거 데이터를 그대로 시나리오로 사용하는 것이다(rolling window 방식).
또는 부트스트래핑을 통해 기존 시나리오 집합에서 표본을 다시 추출하여 집합을 구성할 수 있다.
문제는 이러한 방법들은 단 한 번 발생한 극단적인 사건에 대해 신뢰수준을 매우 높게 잡지 않는 이상 VaR에 반영되기가 어렵다는 점이다. 이를 보완하는 방법으로 과거 관측치들에 가중치를 부여해서 장기적인 기억을 유지하도록 할 수 있는데, 상황에 따라 가중치를 조절할 수 있다.
실무적으로는 두 종류의 시나리오를 함께 사용하는 것이 바람직한데, 하나는 현재 시장 상황과 최근 이력을 반영한 중간 수준의 시나리오 집합, 다른 하나는 과거의 주요 주식, 채권, 통화시장 위기를 반복한 극단적 시나리오 집합이다. 이들 시나리오에 대해 합리적인 방식으로 가중치를 부여하여 정보를 반영해줄 수 있다.
또한 과거 데이터만으로 얻은 VaR 추정치는 분포의 꼬리부분에서 생기는 불연속성에 대한 문제가 있는데, 이를 완화하기 위해 과거 관측치에 확률분포를 적합시켜 꼬리 부분을 모델링한 후 VaR을 시뮬레이션한다.
위험 평가를 위한 시나리오 생성에 과거 관측치를 사용하는 것은 실제 발생 사건 반영, 생성이 쉽고 직관적인 이해가 가능하다는 장점이 있는 반면 과거지향적이기 때문에 미래의 위험을 정확히 추정하지 못할 수 있다는 한계점도 존재한다.
8.2.5 Selection of Value-at-Risk Parameters and Regulatory Requirements
VaR을 계산하기 위해서는 두가지 입력 파라미터가 필요하다.
- confidence level 1-ε
- time horizon
일반적으로 time horizon은 2주정도면 충분하다고 가정하며, 단기 기간이 장기보다 VaR 백테스팅 및 검증에 더 자주 사용될 가능성이 높다(데이터가 더 많이 확보되기 때문).
단기간(ex. 1일)의 VaR 추정을 동일한 신뢰수준에서 장기간(ex. 10일)의 VaR 추정으로 변환하기 위해, BIS 규정은 근사 방식을 사용하도록 한다.
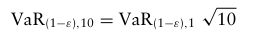
신뢰수준이 증가할수록 VaR 추정이 더 어려워지며, 이는 꼬리 관측치가 점점 줄어들기 때문이다.
8.2.6 Optimization of Value-at-Risk
VaR을 위험 관리 측면 외에도, 포트폴리오 배분 목적으로도 사용할 수 있다.
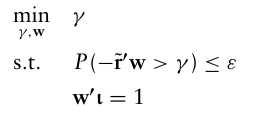
개별 자산 수익률 r벡터에 대해 S개의 가능한 시나리오 데이터가 있다고 하면, VaR 최적화 문제는 다음과 같다.
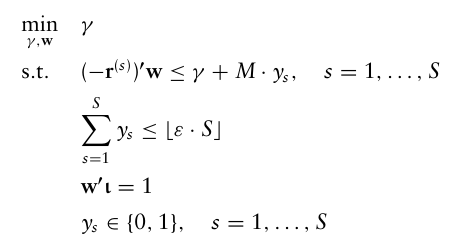
예를 들어 1000개의 시나리오로 구성된 데이터 세트를 고려하면, 해당 문제는 1000개의 이진 변수를 가지는 MIP를 풀어야하기 때문에 매우 오랜 시간이 걸린다.
대안 중 하나는, VaR 최적화를 근사치 또는 추가적인 가정으로 수행하는건데, 수익률이 다변량 정규분포를 따른다고 가정하면, VaR 최적화 문제를 다음과 같이 작성할 수 있다.
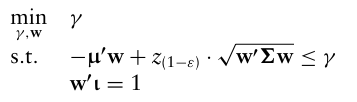
다만 이렇게 얻은 포트폴리오는 MVO와 동일한 단점을 가진다(평균과 표준편차만으로 최적화를 수행하기 때문).
8.2.7 Arguments For and Against Value-at-Risk
VaR 이전의 다양한 리스크 측정 지표들이 특정 자산에만 국한되어있다는 단점을 해결하고, VaR은 주식, fixed income 및 기타 다양한 자산들의 위험을 일관되게 비교할 수 있다.
그러나 초창기에 여러 전문가들은 이러한 모델링이 복잡한 금융시장의 움직임을 너무 단순하게 표현하려고 하기 때문에 잘못된 모델이라고 주장하기도 했다.
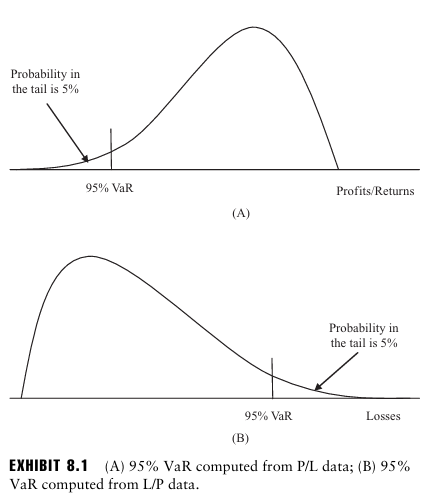
실제로 VaR은 극단적인 사건이 발생할 경우에 얼마나 손실을 입을 수 있는지는 알려주지 않는데, 이를 쉽게 이해하는 방법으로 아래의 두 그래프를 볼 수 있다.
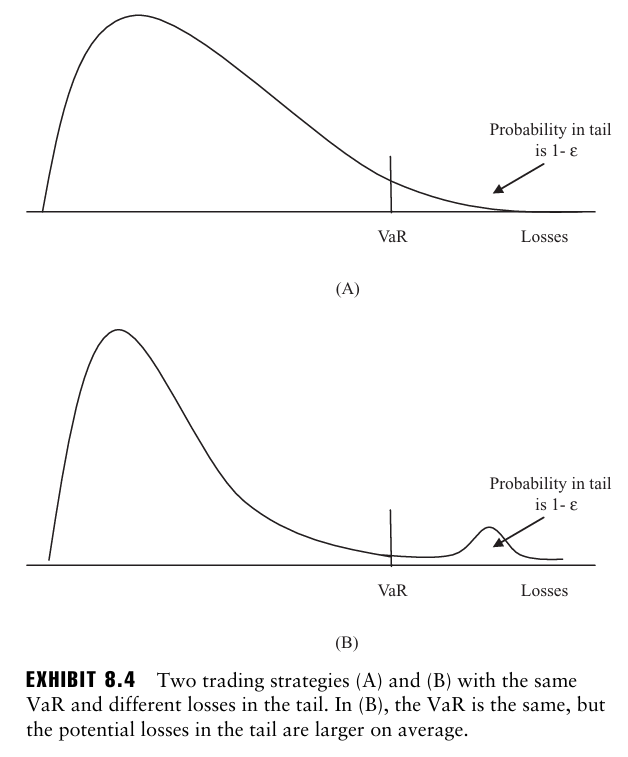
A와 B의 VaR은 동일하지만, 실제로는 B에서 훨씬 더 많은 손실을 겪게 된다. 즉, 임계값을 사용하는 VaR의 특징이 투자자들을 극단적인 손실에 노출시킬 수 있다는 문제가 존재한다.
추가로 시나리오 기반의 VaR 최적화는 불연속하며 비볼록 최적화이기 때문에 시간도 오래걸리고 결과 자체도 전역최적해임이 보장되지 않는다.
마지막으로, VaR의 이론 자체에도 문제가 존재하는데, 분산투자를 했음에도 리스크가 줄어든 것을 제대로 반영하지 못할 수 있다는 것이다.
ex. 액면가가 100달러인 두 개의 무이표채 A, B를 고려해보자.
A는 현재 97달러이며 만기에 111.55달러를 지급받고, B는 현재 90달러이며 만기에 103.5달러를 지급받는다. 두 채권 모두 부도확률은 4%이다.
A는 약속대로 지급된다면 14.55의 이익을, 부도난다면 97의 손실을 입는다. 문제는 95% VaR은 5%의 임계값을 보기 때문에 4%로 발생하는 부도에 따른 손실을 반영하지 못한다는 것.
따라서 A의 95% VaR은 -14.55가 된다.
B의 경우도 마찬가지로 95% VaR은 -13.5가 되므로 두 자산의 VaR 합은 -28.05가 된다(즉 28.05달러만큼의 이익).
이제 이 두 자산을 매수하여 만든 포트폴리오의 손실을 비교해보면,

누적 확률이 95%가 되는 손실 값이 75.45달러인데, 사실 이는 95% VaR임을 알 수 있다.
분명 아까 A,B의 각 95% VaR을 더한게 -28.05인데 오히려 두 자산을 매수한 포트폴리오의 95% VaR이 75.45로 훨씬 크니 투자자는 분산 투자를 하지 않고 A또는 B 하나만 매수하는 전략을 펼치게 될 것.
따라서 VaR이 이러한 복합 위험을 계산하는 것에 적합하지 않다는 문제가 존재한다.
8.3 CONDITIONAL VALUE-AT-RISK AND THE CONCEPT OF COHERENT RISK MEASURES
기존의 VaR의 단점을 고려하여 Artzner, Delbaen, Eber and Heath(2001) 이 coherent risk measures 라는 측정치를 제안했다.
위험 측정치 $\rho$ 는 다음 조건들을 임의의 두 확률변수 $\tilde x$ 와 $\tilde y$ 에 대해 만족하면 이는 coherent risk measures이다.
- Monotonicity.If $\tilde x ≥ 0$ , then $ρ(\tilde x) ≤ 0$ .
- Subadditivity. $ρ(\tilde x + \tilde y) ≤ ρ(\tilde x) + ρ(\tilde y)$ .
- Positive homogeneity. For any positive real number c, $ρ(c · \tilde x) = c · ρ(\tilde x)$ .
- Translational invariance. For any real number c, $ρ(\tilde x+ c) ≤ ρ(\tilde x) − c$ .
즉, 양의 수익만 있는 경우 위험은 0이어야 하며(1), 두 자산으로 이루어진 포트폴리오의 위험은 개별 자산의 위험 합보다 작거나 같아야 하며(2), 포트폴리오의 자산 양의 c배로 증가하면 위험도 c배로 증가하고(3), 현금 또는 다른 무위험 자산은 포트폴리오 위험에 기여하지 않는다(4).
VaR은 이 조건중 2번 조건을 위반하며, 표준편차는 1번 조건을 위반한다.
이들은 CVaR(conditional value-at-risk)을 새롭게 제안했으며 이는 4가지 조건을 모두 만족하며, VaR과도 관련이 있다.
VaR은 주어진 확률 ε로 최대 손실만을 고려하는 반면, CVaR은 손실이 해당 확률을 초과할 경우 평균적으로 얼만큼의 손실이 일어날지를 알려준다.
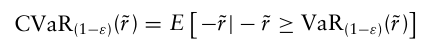
이는 같은 ε 하에서 항상 VaR보다 크거나 같으며, 손실이 정규분포를 따른다고 가정하거나 포트폴리오 수익률의 가능한 실현에 대한 시나리오 집합이 주어졌을 때는 CVaR을 추정할 수 있다.
8.3.1 Estimation of Conditional Value-at-Risk from a Normal Distribution
데이터가 손익(P/L) 형식이고 정규분포를 따른다고 가정하면, 100(1-ε)% CVaR은 다음과 같다.
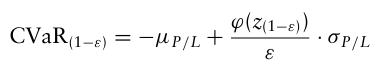
8.3.2 Estimation of Conditional Value-at-Risk from a Discrete Distribution
포트폴리오 손실에 대한 시나리오의 이산 분포가 있고, 손실 금액 $l_j$ 가 확률 $p_j$ 로 발생한다고 가정하면 100(1-ε)% CVaR은 다음과 같다.
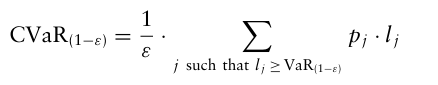
즉, cutoff보다 크거나 같은 손실들에 대해 확률가중평균을 수행한 형태로 만들어진다.
실무에서 자주 접할 수 있는 이산 분포중 하나는 이산 균등 분포로, S개 시나리오 집합 내의 모든 시나리오가 동일한 확률 1/S로 발생할 수 있다.
이 경우 100(1 − ε)% CVaR은 위 식의 p 대신 1/S가 모든 j에 대해 들어가게 된다.
8.3.3 Optimization of Conditional Value-at-Risk
N개의 자산으로 구성된 포트폴리오의 CVaR은 포트폴리오 내 서로 다른 자산의 불확실한 수익과 이 자산들의 포트폴리오 가중치로 이루어진 함수이다.
포트폴리오 수익 $\tilde r_p$ 가 밀도 함수 f를 가지는 확률 분포를 따른다고 가정하면, 100(1 − ε)% CVaR은 다음과 같다.
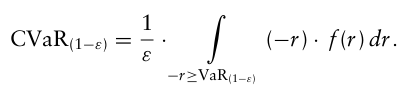
CVaR 정의에 기대값이 존재한다는 것은 포트폴리오의 최소 CVaR을 만드는 자산 배분을 찾고자 할 때 stochastic programming을 사용할 수 있다는 것인데, 문제는 VaR 관점에서 정의된만큼 최적화가 어렵다.
Rockafellar and Uryasev(2000) 은 CVaR 대신 보조 목적함수를 사용하는 것을 제안했는데, 다음과 같이 나타낼 수 있다.
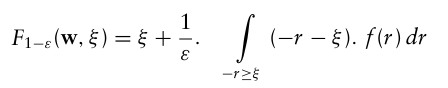
이때 w와 ξ를 변화시켜 이 함수를 최소화하면 함수의 최솟값은 100(1 − ε)% CVaR과 동일하다는 것이 밝혀졌다.
→ 이를 통해 VaR을 찾지 않고도 CVaR의 최솟값을 찾을 수 있다.
또한 CVaR 최소화가 비교적 쉽게 풀리는 특별한 경우가 있는데, 이는 자산수익률의 결합분포를 연속적인 확률밀도함수가 아닌 유한한 개수의 시나리오로 표현할 때다.
실제 실무에서도 이런 형태의 데이터를 많이 쓰는데, 과거 수익률 데이터를 그대로 시나리오로 쓰거나 시뮬레이션으로 시나리오를 만들 수 있기 때문.