최적화 스터디: Asset Diversification and Efficient Frontiers
해당 게시글은 SIMULATION AND OPTIMIZATION IN FINANCE 원서를 리뷰한 글입니다.
7. Asset Diversification and Efficient Frontiers
normative theory VS asset pricing theory
- Normative는 “투자자가 어떤 포트폴리오를 선택해야 하는가?” → 투자 행동에 대한 제시
- Asset Pricing은 “자산의 기대수익률이 왜 그렇게 되는가?” → 가격 원리 및 구조 제시
7.1 THE CASE FOR DIVERSIFICATION
두 주식이 있고. 각각의 기대수익률은 $E[\tilde r_1] = \mu_1 = 9.1\%$ , $E[\tilde r_2] = \mu_2 = 12.1\%$ , 표준편차는 $\sigma_1 = 16.5 \%$ , $\sigma_2 = 15.8\%$ 라고 가정하자.
겉보기에는 주식 2가 주식 1보다 기대수익률도 높고 표준편차도 낮기 때문에 명백하게 더 좋다. 따라서 주식 2에 100% 투자하는 전략이 가장 합리적이라고 할 수 있다.
두 자산 간 상관계수가 $\rho_{12} = -0.22$ 라고 하자. 두 주식의 가중치 합은 1이 되어야 하므로 $w_2 = 1 - w_1$ 임을 고려했을 때, 포트폴리오 수익률은 다음과 같다.
$\tilde r_p = w_1 \tilde r_1 + w_2 \tilde r_2$
이 포트폴리오의 기대수익률과 분산은,
$E[\tilde{r}_p] = E[w_1 \tilde{r}_1 + w_2 \tilde{r}_2] = E[w_1 \tilde{r}_1] + E[w_2 \tilde{r}_2] = w_1 E[\tilde{r}_1] + w_2 E[\tilde{r}_2] = w_1 \mu_1 + w_2 \mu_2$
$\sigma_p^2 = Var(w_1 \tilde{r}_1 + w_2 \tilde{r}_2) = Var(w_1 \tilde{r}_1) + Var(w_2 \tilde{r}_2) + 2Cov(w_1 \tilde{r}_1, w_2 \tilde{r}_2) = w_1^2 \sigma_1^2 + w_2^2 \sigma_2^2 + 2 w_1 w_2 \sigma _{12}$
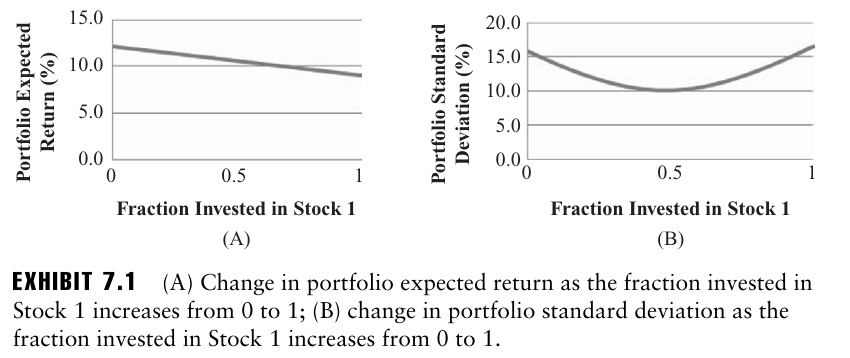
EXHIBIT 7.1은 포트폴리오 수익률고 ㅏ표준편차가 포트폴리오의 주식 1에 투자된 비율에 따라 어떻게 변화되는지를 보여준다.
- 포트폴리오 기대수익률은 주식 1에 투자를 아예 안할 때 가장 높지만, 표준편차는 꽤 높은 편임을 알 수 있다.
- 따라서 주식 1과 주식 2에 모두 투자함으로써 포트폴리오의 표준편차를 더 낮춰줄 수 있다.
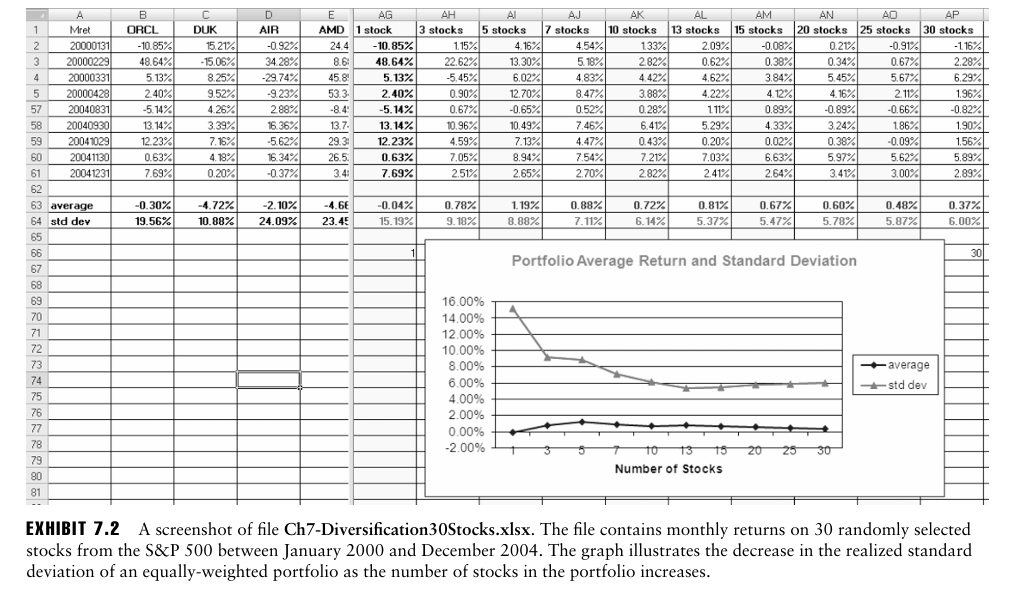
이는 자산간 약한 상관관계만 있어도 다각화 효과가 발생하는데, EXHIBIT 7.2의 주식들의 평균 상관관계는 작은 양수값임에도 불구하고 동일가중 포트폴리오를 구성할 때 표준편차가 감소한다는 것을 볼 수 있다.
그렇다고 분산투자가 반드시 위험을 완전히 제거한다는 것은 아니다. EXHIBIT 7.2의 결과에서 알 수 있는데, 일정 지점부터 주식을 더 추가해도 포트폴리오의 표준편차가 줄어들지 않는 것을 볼 수 있다.
→ 이를 발견한 것이 Evans and Archer(1968)의 연구로, 분산투자의 이점은 10~20개의 주식으로 얻을 수 있다고 언급했다. 반면 Malkiel의 연구는 최근에는 200개의 개별 주식이 있어야 과거 10개정도의 분산효과가 일어날 수 있다고 언급한다.
실제로 Mandelbrot(1963)는 현실 자산 수익률은 stable Paretian distribution을 따르며 확률변수의 분산은 무한하기 때문에 다각화가 잘 이뤄지지 않을 수 있다고 주장한다.
또한 Fama(1965)도 자산 수익률이 stable Paretian distribution을 따른다면 다각화가 더이상 의미가 없을 수 있음을 보여주었다.
→ 다만 실무에서는 일정 수준의 다각화는 바람직하다고 말함.
7.2 THE CLASSICAL MEAN-VARIANCE OPTIMIZATION FRAMEWORK
포트폴리오의 각 자산 i의 가중치 합은 1이므로 $\sum_{i=1}^N w_i = 1$ 으로 나타낼 수 있고, 공매도가 허용될 경우에는 가중치가 음수가 될 수 있다.
포트폴리오의 위험을 구하기 위해 사용되는 공분산 행렬의 경우 대각성분은 자산 i의 분산, 비대각성분은 자산 i와 j의 공분산이 들어있는 대칭행렬 형태이다.
따라서 포트폴리오의 기대수익률과 분산은 다음과 같이 나타낼 수 있다.
$\mu_p = \sum_{i=1}^{N} \mu_i \cdot w_i = \mu’ w$
$\sigma_p^2 = w’ \Sigma w$
고전적인 평균-분산 포트폴리오 배분 문제는 다음과 같다.
$\min \limits_{w} w’ \sum w$
$s.t. \quad w’\mu = r_{target}, \, w’\iota = 1$
모든 제약 조건도 convex하다는 것을 알 수 있다(제약조건이 모두 선형이기 때문에).
목적함수도 결정변수 w에 대해 convex한지 보기 위해 두 자산의 포트폴리오를 고려해보자. $w_2 = 1 - w_1$ 을 이용해 포트폴리오 분산 식을 다시 써보면,
$\sigma_p^2 = w_1^2 \sigma_1^2 + (1 - w_1)^2 \sigma_2^2 + 2 w_1 (1 - w_1) \rho_{12} \sigma_1 \sigma_2 = w_1^2(\sigma_1^2 + \sigma_2^2 - 2\rho_{12}\sigma_1\sigma_2) + w_1(-2\sigma_2^2 + 2\rho_{12}\sigma_1\sigma_2) + \sigma_2^2$
이때 $w_1^2$ 앞에 있는 계수의 부호가 이차식이 concave일지 convex일지를 결정한다.
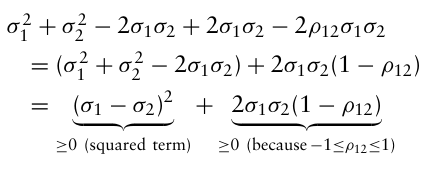
따라서 목적함수와 제약식 모두 convex → 볼록 최적화 → 지역최적해 = 전역최적해 가 성립한다.
최적해는 라그랑주 승수를 사용하여 닫힌 형태의 해를 찾을 수 있는데,
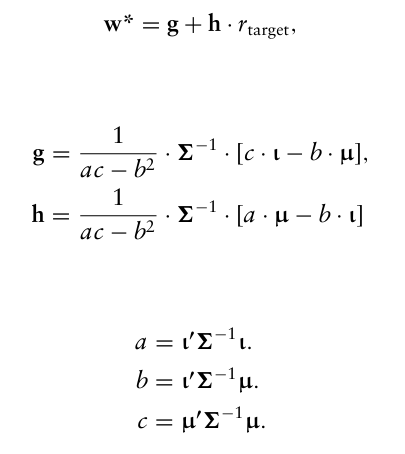
로 나타난다.
하지만 일반적으로 고전적인 MVO는 추가 제약 조건을 포함하거나 목적함수가 다른 방식으로 표현되기 때문에, 닫힌 형태의 해가 존재하지 않으며 최적 가중치를 구하기 위해서는 솔버를 사용해야 한다. 이때 목적함수에 표준편차가 아닌 분산을 사용하는 것이 솔버가 처리하는 데 더 효과적이다(어차피 최적해는 동일).
7.3 EFFICIENT FRONTIERS
7.1에서의 두 주식 예시를 다시 생각해보자. 두 주식의 가중치에 따라 포트폴리오의 위험-수익 조합이 서로 다르게 나타나는데, 어떤 위험-수익 조합이 최적인지 말하는 것은 어렵다.
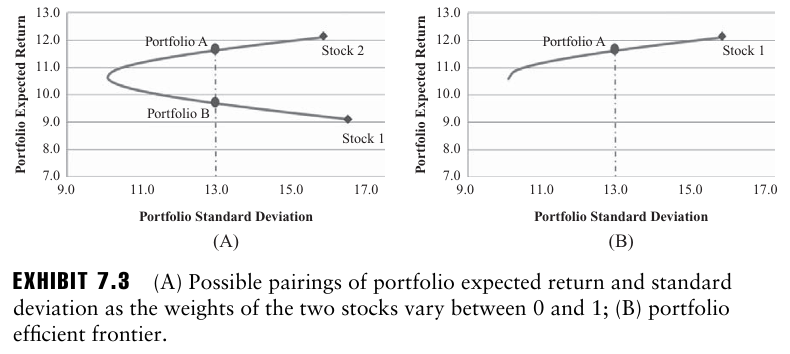
이는 개인이 위험 감수 정도에 따라 달라지기 때문. 하지만 적어도 오답은 있다. EXHIBIT 7.3의 A 그림에서, 동일한 위험에서 11% 이상의 기대수익을 가지는 포트폴리오 A보다 약 10%의 기대수익을 가지는 포트폴리오 B를 선호하는 사람은 없을 것.
B 그림은 효율적 경계선(Efficient Frontier)를 보여준다. 이는 곡선의 상단을 의미하며, 위험 수준이나 기대수익률에 대해 가장 효율적인 포트폴리오 집합이다.
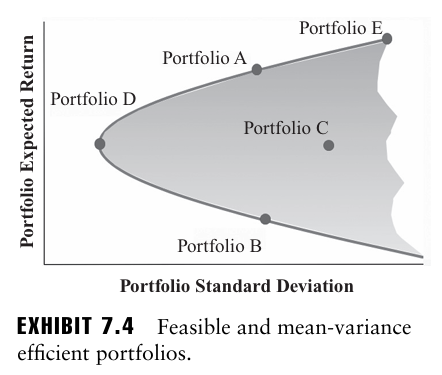
자산 개수를 N개로 늘려보자. EXHIBIT 7.4에서 이 자산들로 구성된 포트폴리오들은 음영 처리된 영역을 채우게 된다. 이때 MVO는 곡선의 상단, 즉 Efficient Frontier에 위치하도록 한다.
포트폴리오 D는 모든 자산의 가중치 조합 중 가장 낮은 포트폴리오 표준편차를 가지는 조합으로, 이를 최소 분산 포트폴리오(minimum variance portfolio)라고 부른다.
7.4 ALTERNATIVE FORMULATIONS OF THE CLASSICAL MEAN-VARIANCE OPTIMIZATION PROBLEM
7.4.1 Expected Return Formulation
MVO에서 목적함수에 포트폴리오 분산을 두고 제약식에 기대수익률 제약을 두는 것 대신, 목적함수에 기대수익률을 두고 제약식에 포트폴리오 분산 제약을 두는 방법도 있다. 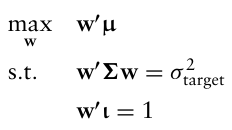
7.4.2 Risk Aversion Formulation
또다른 방법으로는 목적함수에 위험과 수익 간의 상충 관계를 직접 넣는것. 이 방법은 투자자의 위험회피지수 $\lambda$ 를 활용하여 구성할 수 있다.
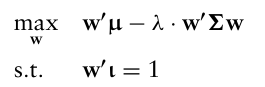
위험 회피 지수 $\lambda$ 는 Arrow-Pratt risk aversion coefficient 라고도 부른다. 람다가 작을수록 위험회피 정도가 낮아지기 때문에 목적함수에서 포트폴리오 분산에 대한 패널티가 줄어들어 더 위험한 포트폴리오가 생성된다. 이 $\lambda$ 값을 바꾸면서 최적화를 풀면 사실상 효율적 경계선 상의 모든 포트폴리오를 계산할 수 있다.
실제 포트폴리오 배분 과정에서, 위험 회피 지수는 대략적으로 2~4 사이에 존재한다.
7.5 THE CAPITAL MARKET LINE
이전까지는 위험 자산의 최적 포트폴리오를 선택하기 위한 Markowitz의 프레임워크에 대해서 다뤘지만, Sharpe(1964), Lintner(1965), Tobin(1958)가 입증한 것처럼 위험이 없는 자산(risk-free asset)에도 투자할 수 있는 투자자에게 제공되는 효율적 경계선은 위험 자산으로만 구성된 효율적 경계선보다 더 우수하다.
위험이 있는 자산과 없는 자산을 동시에 고려할 때, 포트폴리오 수익률은 다음과 같다.
$w’r + (1-w’\iota)r_f$
이때 무위험 자산의 수익률은 고정되어 있는 것으로 가정하므로, 포트폴리오 기대수익률과 분산은 각각 다음과 같다.
$w’\mu + (1+w’\iota)r_f$
$w’\sum w$
따라서 최소분산 포트폴리오 최적화 문제 및 최적해는 다음과 같이 나타난다.
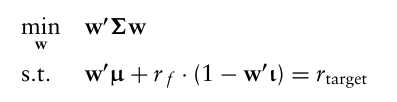
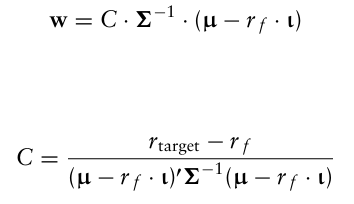
이 위험 포트폴리오는 tangency portfolio라고도 부른다. 특정 가정 하에서, tangency portfolio는 투자자가 이용할 수 있는 모든 자산으로 구성되어야 하며, 각 자산은 모든 자산의 총 시장가치에 대한 자신의 시장 가치 비율에 따라 보유되어야 한다는 것을 보여줄 수 있다.
따라서 tangency portfolio는 market portfolio 또는 market이라고도 부른다.
이 포트폴리오는 목적함수에 포트폴리오의 샤프비율을 최대화하도록 하는 최적화 문제의 해와 동일하다.
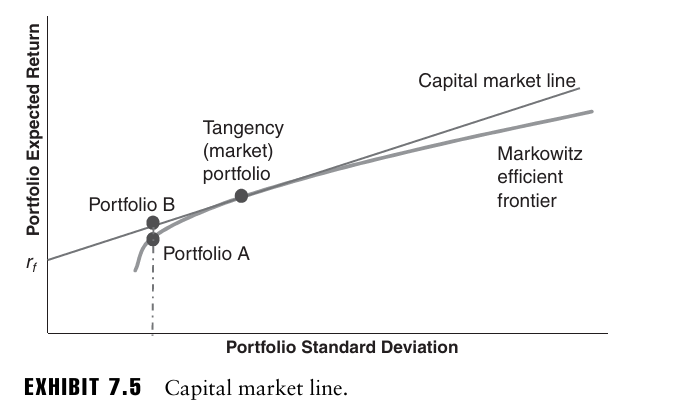
이러한 tangency portfolio와 무위험 자산을 이은 선을 자본시장선(CML)이라고 부르며, 효율적 경계선에 있는 모든 위험 포트폴리오들은 이 CML 위에 있는 포트폴리오보다 열등하다.
여기서 시장 포트폴리오의 왼쪽에 있는 CML 상의 포트폴리오는 위험자산과 무위험자산의 조합을, 오른쪽에 있는 CML 상의 포트폴리오는 무위험자산을 공매도(차입)하여 위험자산의 가중치가 1이 넘도록 하는 포트폴리오이다.
따라서 포트폴리오 구성은 다음의 두 단계로 축소된다.
- Asset allocation: 투자자의 무위험 자산과 위험 자산의 배분을 어떻게 할지 결정.
- Risky portfolio construction: 위험자산들 간의 구성을 어떻게 할지 결정.
만약 모든 투자자가 포트폴리오의 일부를 무위험 자산에 투자하고, 일부를 시장 포트폴리오에 투자한다면, 이들의 포트폴리오 기대수익률 $E[r_p]$ 는 다음과 같다.
$E[r_p] = w_{rf} \cdot r_f + w_M \cdot E[r_M]$
이때 위험자산과 무위험자산의 가중치 합은 1이 되어야 하므로, 다음과 같이 변형하여 쓸 수 있다.
$E[r_p] = r_f + w_M \cdot (E[r_M] - r_f)$
무위험 자산의 수익률과 시장 포트폴리오의 수익률은 상관관계가 없고, 무위험 자산의 분산은 0이므로, 포트폴리오 분산은 다음과 같다.
$\sigma_p^2 = w_{rf}^2 \sigma_{rf}^2 + w_M^2 \sigma_M^2 + 2 w_{rf} w_M \sigma_{rf} \sigma_M \rho(r_f, M) = w_M^2 \sigma_M^2$
따라서 시장 포트폴리오의 가중치 $w_M$ 은 다음과 같다.
$w_M = \frac{\sigma_p}{\sigma_M}$
이 식을 다시 포트폴리오 기대수익률 식에 쓰면, CML에 대한 방정식이 나온다.
$E[r_p] = r_f + (\frac{E[r_M] - r_f}{\sigma_M}) \cdot \sigma_p$
여기서 $(\frac{E[r_M] - r_f}{\sigma_M})$ 을 risk premium이라고 부르기도 하며 CML의 기울기, 즉 위험을 1단위 더 감수할 때 필요한 추가 기대수익을 의미하므로 equilbrium market price of risk라고도 부른다.
7.6 EXPECTED UTILITY THEORY
고전적인 Markowitz 프레임워크에서 위험과 수익 사이의 균형을 가지는 포트폴리오 가중치를 찾도록 최적화를 풀 때, 또다른 방법으로는 투자자의 위험 선호를 효용함수를 통해서 표현하는 것이다.
투자자의 효용함수는 부(wealth)의 수준에 대해 가치(value)를 부여하는 함수로, 기대효용 프레임워크는 “합리적인 투자자는 자신의 포트폴리오 배분 w를 선택할 때, 한 기간 후 자신의 기대 효용을 최대화하도록 선택한다.” 라는 아이디어에 기반한다.
투자자의 효용함수를 $u$ 라고 하고, 기간 말의 wealth를 $\hat W$ 라고 하자.
투자자의 목표는 $E[u(\hat W)]$ 를 최대화하는 것으로, 기간 말에 가능한 여러 wealth의 결과물에 대해 효용을 계산한 후 평균을 낸 것이다.
만약 시점 0에서 wealth가 $W_0$ 이라면, 기대 효용 최적화 문제는 다음과 같이 구성된다.
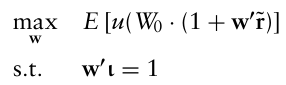
Markowitz 프레임워크는 두 가지 경우에서 기대효용 이론과 일관되는데,
- 자산 수익률이 정규분포를 따른다고 가정할 때
- 수익률이 다변량 정규분포를 따른다면, 확률적 특성은 수익률의 평균, 분산, 공분산만으로 완전히 설명될 수 있다.
따라서 포트폴리오 수익률 $w’ \hat r$ 을 평균, 분산, 공분산의 함수로 표현할 수 있으므로 투자자의 기대효용함수 또한 평균, 분산, 공분산에만 의존한다.
이는 MVO의 철학과 일치한다.
- 수익률이 다변량 정규분포를 따른다면, 확률적 특성은 수익률의 평균, 분산, 공분산만으로 완전히 설명될 수 있다.
- 투자자의 효용함수가 이차형식(quadratic utility function)이라고 가정할 때
※ Quadratic Utility Function
다음과 같은 형태를 가지는 함수.
$u(x) = x - \frac{b}{2}x^2, \quad b>0$
이때 $x = W_0 \cdot (1+w’\hat r)$ 을 대입하면 기대효용에 대한 식은 다음과 같다.
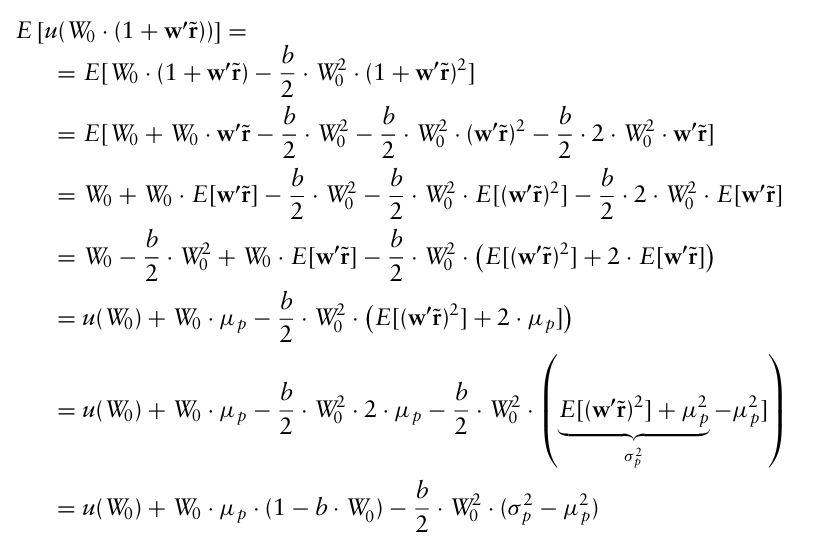
포트폴리오의 평균과 분산은 이차 효용함수를 가진 투자자의 기대효용을 설명하는 데 충분하다. 포트폴리오의 기대수익률을 증가시키면 투자자의 기대효용이 증가하고, 포트폴리오 표준편차를 감소시키면 투자자의 기대효용이 감소하는데, 이는 MVO 프레임워크와 일치함을 알 수 있다.
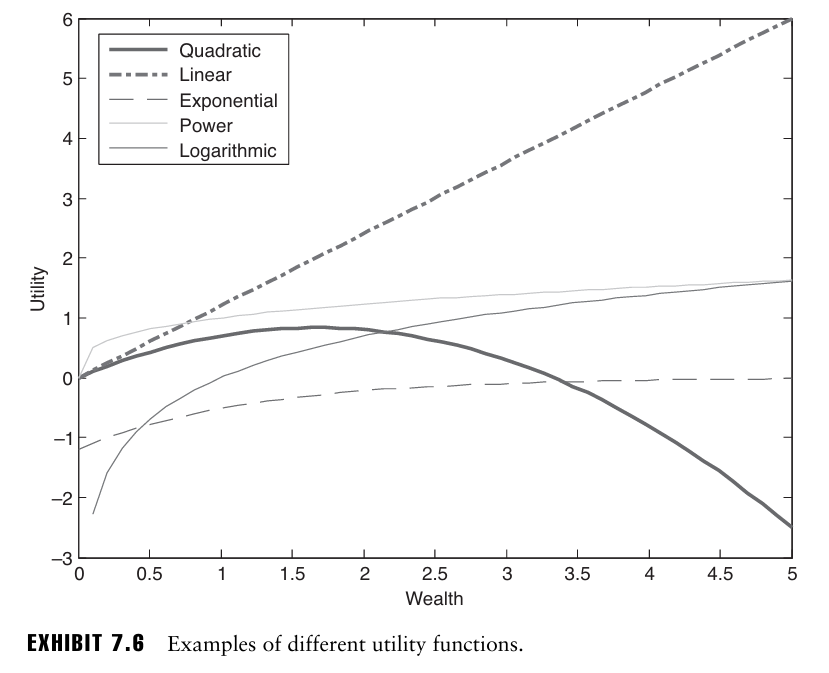
EXHIBIT 7.6은 이차효용 함수의 일반적인 형태로, 이차효용함수는 투자자 행동에 대해 다소 비현실적인 가정을 한다. 바로 이 함수가 단조롭게 증가하지 않고 특정 부분에서 점차 감소한다는 점인데(자산이 증가할수록 투자자의 효용이 증가하는게 현실적), 그럼에도 불구하고 첫번째 가정인 정규분포 가정을 통해 Markowitz 모델을 정당화한다.
Markowitz 모델이 유용한 이유 중 하나는 다른 효용 함수들에 대한 근사값을 제공하기 때문인데, 널리 사용되는 효용함수의 형태는 투자자가 위험 회피적이라고 가정한다. 위험 회피 투자자는 불확실한 보상의 기대효용이 항상 그 보상의 기대값에서 얻는 효용보다 작거나 같은데, 이를 수학적으로 보면 위험 회피 투자자의 효용 함수는 concave한 형태를 가진다는 것을 나타낸다.
반면 직선 형태의 효용함수는 위험 중립 투자자를 의미하며, 불확실한 보상의 기대효용이 그 보상의 기대값에서 얻는 효용과 동일한 상황이다.
이렇게 효용함수가 더 많이 휘어질수록 투자자는 더 강한 위험 회피 성향을 가지는 것으로 가정한다.
※ Linear Utility Function
가장 단순한 형태의 효용 함수로, $u(x) = a+ b \cdot x$ 로 표현할 수 있다.
선형 효용 함수는 투자자가 위험에 중립적이라고 가정, 즉 이러한 투자자들이 관심 있는 것은 기대수익 뿐이며 위험은 고려하지 않는다는 것을 의미한다.
기간 말의 기대효용함수는 다음과 같다.
$E[u(\hat W)] = a + b \cdot E[\hat W]$
이때 기간 말의 wealth에 대한 기댓값은 $u(E[\hat W]) = a + b \cdot E[\hat W]$ 로 두 값이 동일하다.
※ Exponential Utility Function
지수 효용 함수는 다음과 같은 형태를 가진다.
$u(x) = -\frac{1}{a}e^{-ax}, \quad a>0$
이 효용함수는 음수 값을 가지지만 단조 증가하기 때문에 부(wealth)의 수준이 다를 때 상대적 효용을 비교할 수 있다.
※ Power Utility Function
$u(x) = ax^a, \quad 0<a \leq 1$
※ Logarithmic Utility Function
$u(x) = ln(x)$
(x>0 일 때만 정의됨)
일반적인 효용 함수는 기간 말 예상 wealth의 기대값 주변에서 기대효용을 테일러 급수로 전개하면 평균-분산 최적화 형태로 근사할 수 있다.
기말 부의 기대값을 $\hat W$ 로 표시하면,
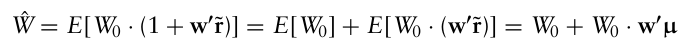
기간말 기대 효용은 기간말 wealth의 기대값 $\hat W$ 를 중심으로 테일러 급수로 전개된다.
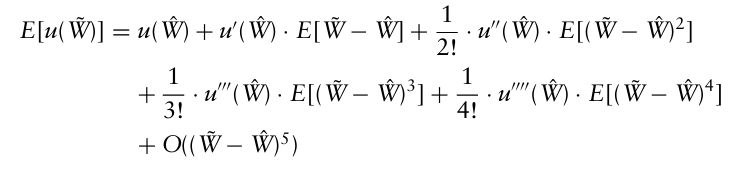
$E[(\tilde{W}-\hat{W})^{k}]$ 를 central moments라고 하며, 이때 $E[W − \hat W] = E[W]− \hat W = 0$ 이므로, 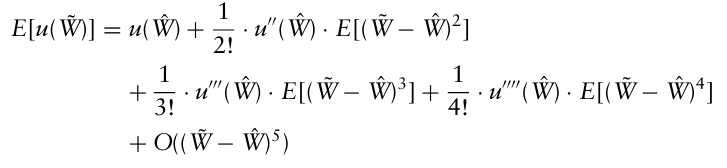
첫 번째 항은 기댓값, 두번째 항은 분산, 세번째 항은 왜도, 네번째 항은 첨도이며, 그 이후의 항들은 더 높은 차수의 central moment와 관련된다.
지금까지 연구결과들은 log utility 또는 power utility를 가진 투자자에게는 MVO가 매우 잘 작동한다는 것을 보였다. 반면 불연속 효용함수나 S자 형태의 효용함수는 이러한 결과가 더이상 성립하지 않는다.