최적화 스터디: Optimization Modeling
해당 게시글은 SIMULATION AND OPTIMIZATION IN FINANCE 원서를 리뷰한 글입니다.
5.1 OPTIMIZATION FORMULATIONS
최적화 문제 공식은 세 부분으로 구성된다.
- 결정 변수 집합
- 결정 변수의 함수인 목적 함수(f(x))
- $(g_i(x), h_j(x)), i=1,…,I \, j=1,…,J$ 로 정의된 제약 조건 집합. 일반적인 형태는 $g_i(x) \leq 0$ 및 $h_j(x) = 0$
→ 제약이 없는 최적화는 “비제약 최적화”라고 불림.
결정변수는 내릴 결정을 나타내는 수치적인 양을 의미하며, 포트폴리오 예제의 경우 포트폴리오 가중치 또는 각 자산군에 배분할 금액이 결정변수가 될 수 있다.
또한 목적함수는 목표에 대한 수학적 표현이며, 제약 조건은 비즈니스 상황에서의 제한을 수학적으로 표현한 것이다.
→ 포트폴리오 예제에서 목적함수는 기대수익률 함수, 제약조건은 총 포트폴리오 위험 식일 수 있다.
결정변수, 목적함수, 제약식이 설정되면 이를 통해 감수할 수 있는 위험의 상한을 고려하여 목적함수의 값을 최대화 or 최소화하는 결정변수 값을 찾게 된다. 이렇게 얻은 결정변수 값을 최적해 라고 부른다.
비제약 최적화의 경우 일반적으로 미적분학의 표준 기법을 사용하여 해결하게 되는데, 제약 조건이 있는 경우는 의사결정 변수 x의 N차원 공간 안에서 제약 조건이 성립하는 일부 점만이 가능해지게 된다.
포트폴리오 예시를 들면, 포트폴리오의 기대수익률 $w\mu$ 를 목적함수에 넣음으로써 다음과 같이 최적화를 수행할 수 있다.
$\max\limits_{w} \; w^\top \mu$
이때 전통적인 최적화 솔버에서는 입력변수에 정해진 값이 들어가야 하며, 확률변수가 들어갈 수 없다.
→ ex. portfolio return = $w’\tilde r$, $\tilde r = (\tilde r_1, …, \tilde r_N)’$
강건 최적화(robust optimization), 확률적 프로그래밍(stochastic programming)과 같은 최적화 분야에서는 입력 데이터가 불확실성을 가지며 이론적 또는 경험적 확률분포를 따르는 최적화 문제를 해결하는 방법론들을 연구한다.
→ 그러나 결국 이러한 방법들 또한 특정 방식으로 기저 확률 분포를 대표하는 고정된 숫자로 최적화를 진행한다.
5.1.1 Minimization vs. Maximization
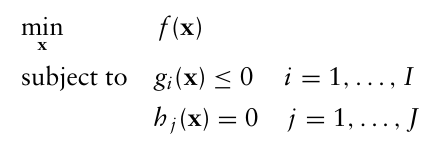
일부 최적화 소프트웨어는 최소화 문제에 대한 최적화 문제만 풀 수 있는데, 최대화 문제를 풀어야 할 경우에는 단순히 목적함수에 -를 곱해서 최소화 문제로 풀어주면 된다.
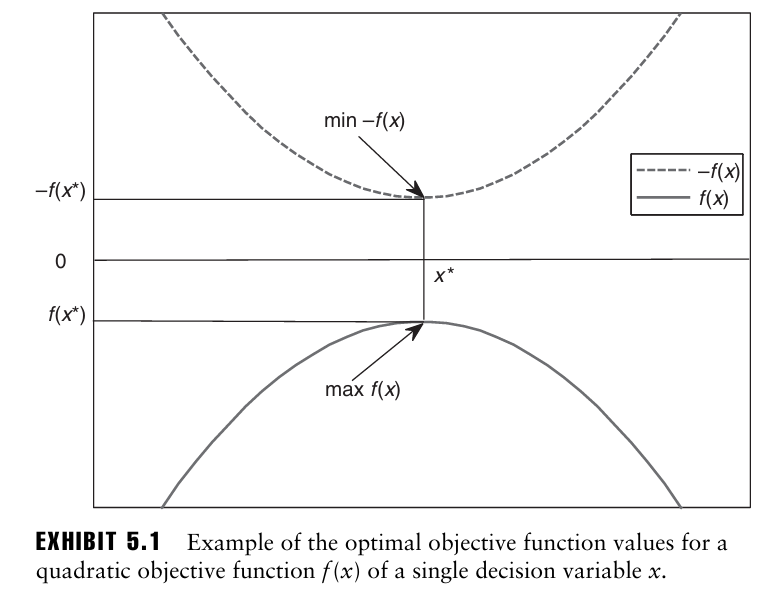
EXHIBIT 5.1은 한 변수 x의 2차 함수에 대한 상황을 보여주는데, max f(x)의 최적값은 최적해 x*에서 얻어진다. 이는 min -f(x) 의 최적값과 동일하다.
ex. 포트폴리오 수익률 최적화 문제
→ $\max\limits_{w} \; w^\top \mu = \min\limits_{w} \; -w^\top \mu$
5.1.2 Local vs. Global Optima
최적화에서는 최적해를 전역최적해와 지역최적해로 구분하는데, 전역최적해는 모든 실행 가능한 해 집합에서 결정변수 벡터 x의 어떤 값에 대해서도 최상의 해를 의미하며, 지역최적해는 실행 가능한 해의 근처에서 가장 좋은 해를 의미한다.
즉 지역최적해 근처의 어떤 지점에서의 목적함수 값은 지역최적해에서의 목적함수 값보다 나쁘지만, 지역최적해는 전역최적해보다 목적함수 값이 나쁠 수 있다.
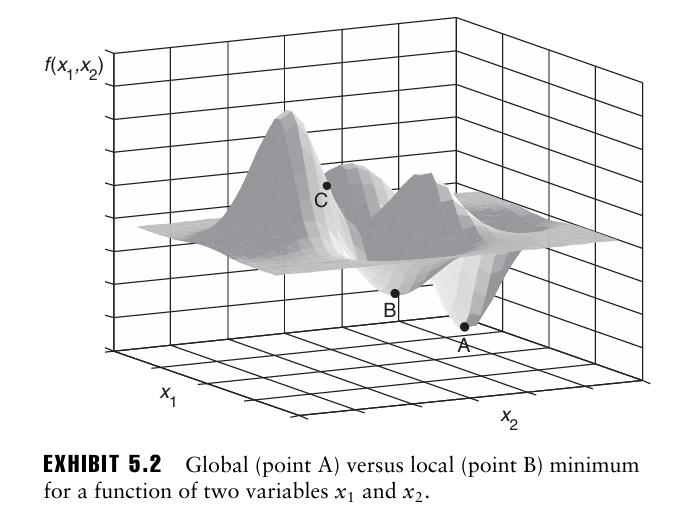
EXHIBIT 5.2는 두개의 결정변수를 가지는 함수의 비제약 최소화 문제에서 전역최적해(A)와 지역최적해(B)를 나타낸다.
대부분의 고전적인 최적화 알고리즘은 지역최적해만 찾을 수 있었는데, 한 점에서 시작하여 목적함수 값이 개선되는 방향으로 해를 탐색하였기 때문에 좋은 시작점을 선택하는 것이 굉장히 중요했다.
→ 이는 지역최적해에 빠져버려서 전역최적해를 찾지 못하게 될 수 있음.
일반적으로 전역최적해를 찾는 것은 어렵고 시간이 많이 걸리며, 먼저 모든 지역최적해를 찾은 후에 그중에서 최상의 해를 선택하는 과정을 가진다.
경우에 따라 최적화 알고리즘이 목적함수와 제약조건의 특수한 구조를 탐색하여 더 강력한 결과를 도출할 수 있으며, 일부 최적화 문제의 범주에서는 지역최적해가 사실상 전역최적해라는 것이 보장된다.
→ 금융 분야의 많은 최적화 문제들이 이러한 특성을 지님.
따라서 주어진 상황에서 최적화 문제의 유형을 인식하고 최적화 알고리즘이 특정 문제 구조를 활용할 수 있도록 최적화 문제를 만드는 것이 중요하다.
5.1.3 Multiple Objectives
우리는 여러 목표를 동시에 최적화하고 싶은 상황이 종종 존재한다.
ex. 포트폴리오 매니저가 포트폴리오 기대수익률과 왜도를 최대화하면서 분산과 첨도는 최소화하는 것이 목표
→ 다목적 최적화 문제는 단일 목표 최적화 문제로 재구성해야함.
이를 수행하는 데 일반적으로 사용되는 방법으로는,
- 서로 다른 목표에 가중치를 부여하고, 목표들의 가중합을 단일 목표 함수로 최적화
- 가장 중요한 목표를 최적화하고, 다른 목표들을 제약 조건으로 포함시켜 각 목표에 대해 허용 가능한 값의 범위를 설정
5.2 IMPORTANT TYPES OF OPTIMIZATION PROBLEMS
최적화 문제는 목적 함수와 제약 조건의 형태, 결정 변수의 종류에 따라 분류될 수 있다.
최적화 문제가 어떻게 표현되느냐에 따라 솔버가 문제의 특수한 구조를 활용할 수 있는지, 그리고 보다 강력한 결과를 얻을 수 있는지 결정된다.
5.2.1 Convex Programming
볼록 최적화(Convex Optimization) 문제는 지역최적해가 전역최적해임이 보장되는 좋은 구조를 가지고 있다.
일반적으로 다음과 같은 형태를 띄는데,
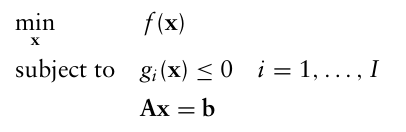
이때 $f(x)$ 와 $g_i(x)$ 모두 볼록 함수이며, $Ax = b$ 는 선형 방정식이다.
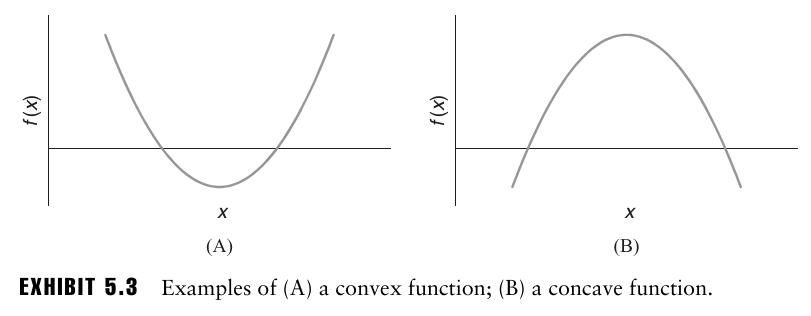
단일변수 x의 볼록함수는 다음과 같은 형태를 가지는데, 볼록함수는 곡선 위의 임의의 두 점을 연결하는 선이 항상 곡선 위에 위치하며, 오목 함수는 곡선 위의 임의의 두 점을 연결하는 선이 곡선 아래에 위치한다.
볼록 최적화 문제는 선형 계획법(LP), 이차 계획법(QP), 2차 원뿔 계획법(SOCP), 준정부호 계획법(SDP) 등 특수 구조를 가진 여러 문제들을 포함한다. → LP, QP, SOCP, SDP 순으로 해결 난이도가 낮음
5.2.2 Linear Programming
선형 계획법은 목적함수와 제약식이 모두 결졍변수에 대한 선형식으로 이루어진 최적화 문제를 말한다.
$\min_x \; c^\top x \;\text{s.t.}\; Ax = b,\; x \ge 0$
최적화 문제중 가장 해결하기 쉬운 문제 유형으로, 지역최적해가 전역최적해임이 보장되는 볼록 문제이다.
금융 분야에서는 대표적으로 자산 배분 또는 차익거래 기회 식별과 같은 분야에서 등장한다.
5.2.3 Quadratic Programming
이차계획법은 목적함수가 결졍변수에 대해 이차식이며, 제약조건은 결정변수에 대한 선형식인 문제이다.
$\min_x \; \tfrac{1}{2} x^\top Q x + c^\top x \;\text{s.t.}\; Ax = b,\; x \ge 0$
이때 행렬 Q가 양의 준정부호 행렬일 때 목적함수는 볼록성을 띈다.
ex. GMV → 목적함수는 포트폴리오 총 위험으로 2차식, 가중치 합 = 1 선형제약, 공분산 행렬은 양의 준정부호 행렬. 따라서 Quadratic Programming
이 또한 지역최적해가 전역최적해임이 보장되는 문제이다. 그러나 Q가 양의 준정부호 행렬이 아닐 경우에는 이 보장이 깨지게 되며 여러 지역최적해 및 정지점이 존재할 수 있기 때문에 해결이 어려워진다.
5.2.4 Second-Order Cone Programming
$\min_x \; c^\top x \;\text{s.t.}\; Ax = b,\; |C_i x + d_i| \le c_i^\top x + e_i,\; i=1,\dots,I$
이때 $|x|$ 는 Euclidean norm 또는 second norm으로 불리며, 다음과 같이 계산된다.
$|x| = \sqrt{x_1^2 + \cdots + x_N^2}$
LP, 볼록 QP, 그리고 이차 목적함수 식과 이차 제약식을 가진 볼록 문제는 약간의 대수 조작을 통해 SOCP로 다시 표현될 수 있다. 그만큼 이러한 최적화를 푸는 알고리즘은 매우 효율적이며, 일반적으로 robust optimization에서 나타난다.
5.2.5 Integer and Mixed Integer Programming
최적화 문제는 결정변수의 특성에 따라서도 구분되는데, 결정변수가 정수일 경우에는 정수 계획법이라고 부르며 결정변수 일부가 연속적일 경우에는 혼합정수계획법 이라고 부른다. 또한 결졍변수가 0또는 1의 값만 가질 수 있는 경우에는 이진계획법(Binary Programming)이라고 부른다.
자산 배분 관점에서 봣을 때, 실제 운용시에 적용되는 조건들로는 포트폴리오에 보유할 수 있는 최대 자산 수, 최대 거래 횟수, 로트 단위 제약, 고정 거래 비용 등이 존재하는데, 이들은 모두 이산적 결졍 변수를 사용한 모델링에 해당한다.
5.3 OPTIMIZATION PROBLEM FORMULATION EXAMPLES
5.3.1 Portfolio Allocation
비즈니스 예시를 들어 최적화 문제를 풀어보자.
한 포트폴리오 매니저가 1,000만 달러를 투자하는 임무를 맡았다.
이 자금은 뮤추얼 펀드에만 투자해야하며, 다음 4가지를 고려해야한다.
- 공격적 성장 펀드
- 인덱스 펀드
- 회사채 펀드
- 머니마켓 펀드
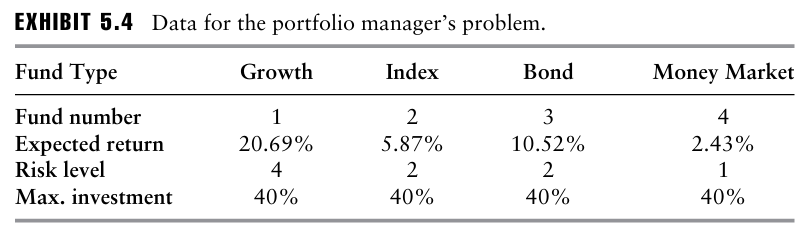
- 신탁 이사회(Board of Trustees)가 설정한 지침은 전체 금액 중 어느 한 종류의 펀드에 할당할 수 있는 금액의 비율을 40%로 제한하는 것.
- 투자 위험을 허용 가능한 수준으로 제한하기 위해 공격적 성장 펀드와 회사채 펀드에 할당되는 금액은 60%를 초과할 수 없음.
- 포트폴리오의 전체 평균 위험 수준은 2를 초과할 수 없음.
- 공매도는 허용되지 않음.
이때 연말에 최대 기대 수익을 달성하기 위한 최적의 포트폴리오 배분은 무엇인가?
※ 최적화 문제 공식화
- 목적함수: 포트폴리오의 기대 수익을 극대화. $f(x) = \mu ‘ x$
- 결정변수: 매니저가 통제할 수 있는 변수. $x =(x_1,x_2,x_3,x_4): amounts (in dollar)$
- 제약식:
- 총 투자 금액은 1,000만 달러 → $x_1 + … + x_4 = 10,000,000$
- 펀드 1과 펀드 3에 투자된 총 금액은 전체 금액의 60%를 초과할 수 없음 → $x_1 + x_3 \leq 6,000,000$
- 포트폴리오의 평균 위험 수준은 2를 초과할 수 없음 → $\frac{4x_1 + 2x_2 + 2x_3 + x_4}{x_1 + x_2 + x_3 + x_4} \leq 2$
- 각 펀드에 대한 최대 투자금은 40%를 초과할 수 없음. → $x_1,x_2,x_3,x_4 \leq 4,000,000$
- 공매도 금지 → $x_1,x_2,x_3,x_4 \geq 0$
위의 세번째 제약식은 선형 제약조건이 아니다. 그러나 계산 측면에서 가능하면 선형 제약조건을 가지는 것이 더 좋기 때문에, 이 제약 조건을 선형 제약 조건으로 변환하는 몇 가지 방법을 살펴본다.
→ 부등식 양쪽에 $x_1+…+x_4$ (양수)를 곱하면 부등식의 부호가 그대로 유지되면서 1번 제약식을 활용하여 다음과 같이 변환시켜줄 수 있다.
$4x_1 + 2x_2 + 2x_3 + x_4 \leq 2*10,000,000$
이제 목적함수를 행렬 형식으로 작성하면,


이 문제는 선형 계획법이 된다. 부등식 제약 조건을 제외하면 5.2.2에서 봤던 선형계획법 표준형태와 비슷해 보인다. 이제 이 부등식 제약 조건을 등식 제약조건으로 변환하여 선형계획법을 표준 형태로 쓸 수 있다.
이를 위해 slack variables 라고 불리는 추가 비음수 변수 $s = (s_1, …, s_6)$ 를 도입하여 부등식 제약조건에 추가해준다.
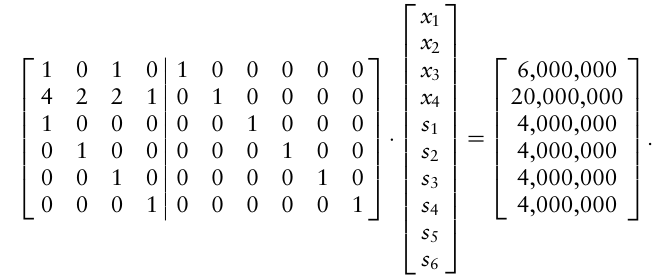
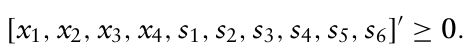
과거에는 최적화 솔버가 문제를 무조건 표준 형태로 전달받아야만 했지만, 최근에는 자체적으로 표준 형식으로 변환이 가능하다.
5.3.2 Cash Flow Matching
정확히 반기별 현금 흐름을 4년동안 은퇴하는 연금 수급자들에게 지급해야 하는 확정급여형 연금 제도의 기업 후원자를 위해 자금을 운용하는 자산운용사의 상황을 고려해보자.
향후 4년동안 8번의 지급일에 대한 현금 의무 $m = (m_1,…,m_8)$ 를 가지며, 자산운용사가 연금 지급을 위해 신용등급이 높은 5개의 채권에 투자하는 것을 고려할 때 채권 i의 쿠폰 지급 흐름은 $c_i = (c_{i1},…,c_{i8})$ 이다.
또한 채권 가격은 $p = (p_1,…,p_5)$ 로 나타나며, 현금흐름 표는 다음과 같다.
자산운용사는 채권의 쿠폰 지급액이 연금제도의 현금 지급 의무를 충족하도록 보장하고자 한다.
즉, 채권을 취득하는 비용을 최소화하면서 모든 미래 연금 지급금을 충족시키도록 투자하는 것.
※ 최적화 문제 공식화
- 목적함수: 채권 투자비용 최소화 → $p’x$
- 결정변수: 5개 채권 각각에 투자할 금액 → $x = (x_1,x_2,x_3,x_4,x_5)$
- 제약조건:
- 각 지급일마다 모든 채권의 쿠폰 지급금이 적어도 부채(연금 지급금)와 같거나 커야 한다 → $\sum_{i=1}^5 c_{it}x_i \geq m_t, t=1,…,8$
- 각 채권 공매도 금지 → $x_i \geq 0$
- 각 채권 투자 금액은 정수(lot 제약) → $z_i integer$
- 채권 i의 거래 단위 $l_i$ 에 대해 각 채권의 최적 구매 단위 수 → $x_i = z_i l_i$
x는 continuous이고 z는 discrete 하기 때문에 이 선형계획 문제는 혼합정수계획법이 되어 조금 더 복잡해지게 된다.
(MIP 문제를 해결하려면 CPLEX와 같은 보다 고급 솔버가 필요함)
5.3.3 Capital Budgeting
제약회사의 운영 관리자는 8개의 서로 다른 R&D 프로젝트에 대한 자금 지원 제안을 고려하고 있다.
자금은 제한되어 있으며(C = 1,000,000 달러), 프로젝트 i에 투자하는 비용은 $c_i$ , 프로젝트 i의 예상 편익의 현재가치는 $b_i$ 이다.

각 프로젝트는 수락하거나 포기하는 방식으로 진행되며 부분적 자금 지원은 불가하다.
이때 운영 관리자는 총 기대 편익의 현재 가치를 극대화하고자 한다. 이를 위해 어떤 프로젝트에 자금을 지원해야 할까?
만약 위 문제를 수식화하지 못할 경우, 또다른 접근 방법으로는 각 프로젝트의 편익 대비 비용 비율으로 순위를 매기고 100만달러의 예산으로 자금을 지원할 수 있는 만큼 프로젝트를 선택하는 것이다.
EXHIBIT 5.6 의 결과를 통해 프로젝트 1,2,3을 선택했다면, 총 비용은 95만 달러, 총 편익의 현재가치는 217만 달러이다.
※ 문제는 5만달러가 남았다는건데, 5만달러로는 실행할 수 있는 프로젝트가 없다.
하지만 프로젝트 3은 20만 달러의 비용, 프로젝트 6은 25만 달러의 비용을 가지기 때문에 이 두 프로젝트를 바꿈으로써 프로젝트 1,2,6에 투자할 경우 얻는 총 이익은 222만 달러이다.
가장 최적의 방법으로는 프로젝트 1,3,4,5에 지원할 경우이며, 이 경우의 총 이익은 223.5만 달러로 가장 큰 이익을 가진다.
→ 어떻게 이 조합을 바로 알아볼 수 있을까?
이렇게 별다른 추가 제약 없이 간단한 문제에 대한 해답을 바로 알아내는 것은 쉽지 않은데, 결졍변수 $x_1, …, x_8$ 을 이진변수로 설정하면 총 이익을 다음과 같이 계산할 수 있다.
$950000 \cdot x_1 + 780000 \cdot x_2 + 440000 \cdot x_3 + 215000 \cdot x_4 + 630000 \cdot x_5 + 490000 \cdot x_6 + 560000 \cdot x_7 + 600000 \cdot x_8$
선택한 프로젝트의 총 비용도 유사한 방식으로 계산하면 다음과 같이 최적화 문제를 만들 수 있다.
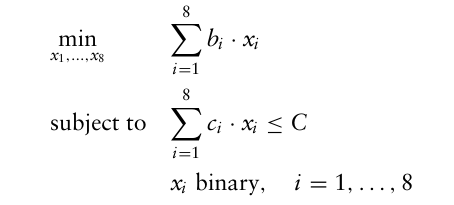
이제 추가 제약을 걸어보자.
- 프로젝트 1에 자금을 지원하면 프로젝트 8에도 자금을 지원해야 한다. → $x_1 \leq x_8$
- 프로젝트 4와 5는 목표가 거의 동일하므로 상호 배타적이다. 즉 둘 중 하나만 지원해야한다. → $x_4 + x_5 \leq 1$
이 경우 최적해는 프로젝트 2,4,6,7 에 투자하는 것이다.
5.4 OPTIMIZATION ALGORITHMS
일반적으로 최적화 알고리즘은 반복적인 성격을 가진다. 초기해로 시작하여 최적해에 가까워질 때까지 일련의 중간 해를 생성하는데, 가까움의 정도는 허용오차라고 불리는 매개변수에 의해 결정된다.
허용오차는 일반적으로 기본값을 가지지만 사용자가 수정할 수 있다. 이 매개변수는 현재 해와 다음 해 사이의 거리를 측정하는 지표, 또는 알고리즘의 반복이 진행되면서 목적함수 값을 얼마나 개선했는지를 나타내는 변화량과 연결되어있다.
만약 알고리즘의 반복이 진행되더라도 현재 상태에 비해 변화가 거의 없으면 알고리즘은 종료된다.
많은 최적화 솔버는 사용자가 특정 문제에 적용할 최적화 알고리즘을 선택할 수 있도록 하며, 다양한 유형의 문제에서 어떤 알고리즘이 사용되는지에 대한 기본적 지식은 어떤 소프트웨어를 사용할지, 어떤 옵션을 선택할지 결정하는 데 도움을 준다.
5.4.1 Linear Optimization: The Simplex Algorithm and Interior Point Methods
최초의 최적화 알고리즘인 심플렉스 알고리즘은 1947년 George Dantzig 에 의해 개발되었으며, 이는 선형 방정식 시스템을 반복적으로 풀어 가능해를 찾아나가면서 목적함수 값을 지속적으로 개선하는 방식으로 문제를 해결했다.
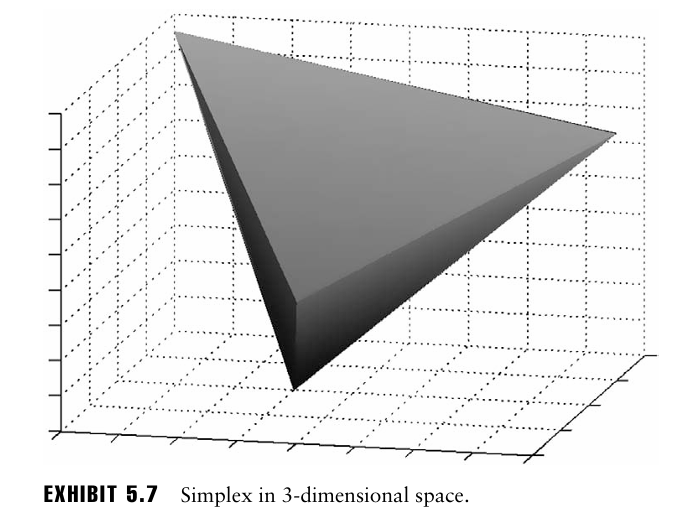
2차원 심플렉스는 삼각형으로, 2+1 개의 점 사이에 그을 수 있는 선들 사이에 존재하는 점들의 집합을 의미한다.
이처럼 N차원 공간에서 심플렉스는 집합 내 가장 바깥 점들을 연결하는 초평면으로 둘러싸인 모든 점들의 집합이다.
선형 최적화 문제에서 결정변수의 가능한 집합은 심플렉스이며, 선형최적화 문제와 관련된 매우 흥미로운 사실은 최소 하나의 최적해가 반드시 심플렉스의 꼭지점에 존재한다는 것.
→ 심플렉스 알고리즘 또한 이를 활용하여 목적함수의 최적값을 제공하는 꼭지점 해를 찾아서 최적해임을 보인다.
이는 오래된 알고리즘임에도 불구하고 여전히 선형 최적화에 널리 사용되며 실무에서도 매우 효율적이다.
1980년대에는 내부점 방법(interior point methods)이라고 불리는 또다른 알고리즘이 개발되었는데, 단순히 가능한 영역의 모서리를 따라 이동하며 꼭짓점만 고려하는 심플렉스와는 달리, 내부점 방법은 가능 영역의 내부에서 출발하여 최적해에 도달한다.
최적해가 여러개일 경우 내부점 방법은 꼭짓점 해를 찾지 못할 수 있다. 따라서 선형 최적화 문제에 최적해가 여러개 있을 경우 심플렉스와 내부점 알고리즘 각각 다른 최적해를 도출할 수 있다.
내부점 방법의 장점은 선형 최적화 문제 뿐만 아니라 더 넓은 범위의 볼록 최적화 문제도 적용할 수 있다는 점이다.
5.4.2 Constrained Nonlinear Optimization: The KKT Conditions and Lagrange Multipliers
많은 비선형 최적화 알고리즘은 해 x가 최적이기 위해 반드시 만족해야 하는 조건을 나타내는 특별한 방정식 집합을 사용하는데, 이것이 바로 Karush-Kuhn-Tucker(KKT) 조건이다.
제약이 없는 최적화 문제이고 목적함수가 미분 가능하다면, 최적해는 미적분학의 표준 기법을 사용해서 구할 수 있는데($f’(x)=0$), 최소화 문제에서 f’(x)가 0보다 작다면 x의 양의 방향으로 이동할 경우 더 작은 f(x) 값을 얻을 수 있고, f’(x*)가 0보다 크다면 음의 방향으로 이동하여 더 작은 f(x) 값을 얻을 수 있다.
여기서 $g_i(x), h_i(x)$ 라는 제약 조건이 생기게 되면 이 제약 함수들의 도함수도 포함이 되어 x*가 다음과 같은 등식을 성립해야 한다.
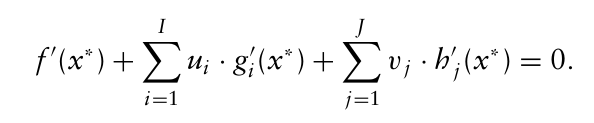
이때 $u_i, v_i$ 는 라그랑주 승수라고 불리며, $u_i$ 는 음수가 아니어야 한다(g가 부등식 제약이므로).
추가로 점 x*가 최적해가 되려면 당연히 가능해여야 하기 때문에 최적화 문제에 포함된 모든 제약조건을 만족해야 한다.
KKT 조건은 이러한 내용을 결졍변수가 여러개인 경우로 일반화한 것으로, 목적함수와 제약함수들의 기울기를 고려하여 x*가 최적해가 되기 위해 다음과 같이 표현될 수 있다.
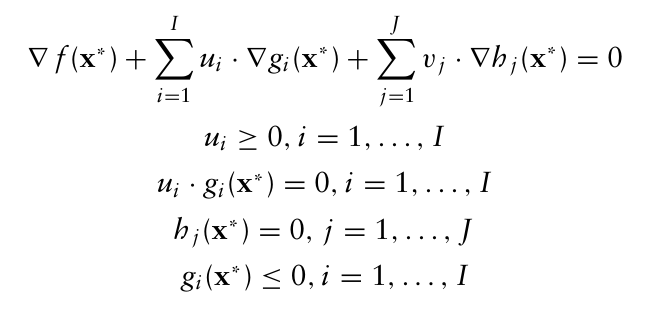
이때 제약함수의 표현식에 따라 일부 방정식이 비선형일 수 있으므로 KKT 조건을 만족하는 점 x를 찾는 것이 쉽지 않을 수 있다. 최적해를 찾더라도 그것이 전역최적해임을 보장할 수 없기 때문인데, KKT 조건은 최적성을 위한 필요 조건이지, 충분 조건은 아니다. 즉 전역최적해는 KKT 조건을 만족해야 하지만 역은 성립하지 않는다.
※ 예외의 경우라면, 볼록 최적화 문제에서는 KKT 조건이 전역최적해에 대한 필요충분조건이다.
→ ex. KKT 조건을 풀기 위해 대표적으로 사용되는 방법인 Newton method도 함수가 볼록이 아닐 경우 초기해를 어떻게 잡느냐에 따라 전역최적해가 아닌 지역최적해에 빠져버릴 수 있음.
일반적인 비선형 최적화에서 KKT 조건은 비선형 최적화 문제를 비선형 방정식 시스템으로 줄일 수 있게 해준다는 점에 있으며 이 방정식의 해는 연속 근사법(successive approximations)을 사용하여 얻을 수 있다. 가장 널리 사용되는 알고리즘은 다음과 같다.
- barrier methods
- primal-dual interior point methods
- sequential quadratic programming methods
Chat GPT
5.4.3 Integer Programming Algorithms
정수계획법 및 혼합정수계획법은 결정변수의 탐색 가능한 값의 수가 연속변수일 때보다 더 적기 때문에 더 쉬워보이는데, 실제로는 정수계획법은 일반적으로 더 어렵고 해결하는 데 더 오랜 시간이 걸린다.
정수라고 해서 모든 가능해를 나열하는 것은 계산 비용이 너무 많이 들기 때문에 알고리즘을 사용해야 하는데, 오히려 정수 결정변수일 때가 알고리즘 적용이 어렵기 때문(불연속해지 때문에).
정수계획법은 일반적으로 branch-and-bound, branch and cut, 그리고 휴리스틱 알고리즘으로 해결되는데, 이러한 알고리즘의 주요 아이디어는 결졍변수가 정수가 아니어도 되는 최적화 문제의 이완형을 먼저 푸는 것에서 시작된다.
초기 단계에서 찾은 해를 바탕으로 정수 해의 범위로 점차 좁혀나가는데, 실제로 초기 단계에서 얻어진 해를 반올림하는 것만으로도 충분한 경우도 있다.
그러나 초기 해를 단순히 반올림하는 것이 실제 최적해와 매우 다른 값으로 이어질 수 있으며, 이는 결졍변수가 많을수록 더 크게 작용한다.
※ 이러한 비선형 혼합 정수 문제를 효율적으로 처리할 수 있는 최적화 솔버는 아직 거의 없는 상황이다.
5.4.4 Randomized Search Algorithms
전통적인 비선형 최적화 알고리즘은 주변 해 중 가장 좋은 해를 찾으면 바로 중단을 하는데, 이 때문에 지역최적해를 찾아버렸을 때 전역최적해에 도달하지 못하고 알고리즘이 종료되버린다.
따라서 여러 알고리즘들이 검색 과정에서 무작위성을 도입함으로써 이러한 함정을 피하고자 하는데, 일정 확률로 오히려 더 나쁜 해로의 이동도 허용하면서 지역최적해에 갇히는 것을 피하고자 한다.
이러한 Randomized Search Algorithms으로는
- simulated annealing
- tabu search
- genetic algorithms
등이 포함된다.
simulated annealing 알고리즘은 최적화 문제에 대한 새로운 가능해를 생성하여 이 해가 목적함수 값을 개선하면 다음 해로 받아들인다.
반면 해가 목적함수의 값을 개선하지 않더라도 일정 확률로 이를 다음 해로 받아들이는데, 이는 매개변수 T(temperature)에 의해 결정된다.
T가 낮으면 simulated annealing 알고리즘이 목적함수 값이 개선되는 경로에서 크게 벗어날 가능성이 적으며, T가 높으면 해를 좀 더 모험적으로 탐색하게 된다.
즉, 알고리즘이 최적값에 가까울 때는 T가 낮아야 알고리즘이 그 근처에서 최적해를 찾지만, 알고리즘 초기 단계에서는 T가 높을 때 알고리즘이 더 빠르게 최적해가 있는 지역을 탐색하게 된다.
(고급 최적화 솔버에서는 T의 기본값이 일반적으로 매우 비선형적이고 어려운 다양한 문제들에서 합리적으로 잘 작동하도록 설정되어 있다.)
유전 알고리즘(genetic algorithms)은 목적함수나 제약조건이 매우 비선형적이거나 불연속성을 가지는 경우에 유용하다.
그러나 유전 알고리즘은 simulated annealing보다 느린 경향이 있는데, 이는 목적함수 값을 더 많이 평가해야 하는 경우가 많기 때문이다.
이러한 단점에도 불구하고 유전 알고리즘이 다른 Randomized Search Algorithms보다 효율적일 수 있는 경우는,
- 결졍변수 중 일부가 정수일 때 → MIP
- 최적화 문제가 특수 구조를 가지는 경우(불연속 등)
유전 알고리즘을 시작하기 전에, 최적화 문제의 가능한 모든 해를 정수의 문자열 형태 또는 binary bits로 인코딩할 수 있는 방법을 먼저 찾아야 한다.
→ 이러한 문자열을 “염색체(chromosome)”라고 한다.
ex. 1101 0000 1111 0010
염색체는 여러개의 유전자로 구성될 수 있으며, 유전자는 개별 비트 혹은 여러개의 비트 묶음일 수 있다.
- Bit(비트): 0, 1, …
- Gene(유전자): 1101
- Chromosome(염색체): 1101 0000 1111 0010
알고리즘이 시작되면, 이러한 염색체들을 일정 수만큼 생성한다.
→ 초기 집단(initial population)
각 염색체에는 적합도 점수가 부여되며, 이는 해당 염색체가 표현하는 해가 얼마나 좋은지를 평가한다.
그 후, 집단에서 두 개의 개체가 무작위로 선택되며 이들을 “부모”라고 볼 수 있다(적합도가 높을수록 부모로 선택될 확률이 높아짐).
사용자가 지정하는 교차율은 부모의 유전자들이 어떻게 서로 교환되는지를 결정하며, 일반적으로 0.7정도로 설정된다. 추가적으로 사용자가 지정하는 돌연변이율(mutation rate)은 평균적으로 몇 퍼센트의 비트가 무작위로 1 → 0 or 0 → 1 로 바뀌는지를 결정한다.
(일반적으로 매우 작게 설정됨. ex. 0.001)
이후 사용자가 지정한 횟수만큼 반복 수행한 후 알고리즘은 종료되며 지금까지 발견된 최적해를 반환한다.
이러한 Randomized Search Algorithms은 계산 속도가 느릴 수 있고 전역최적해를 반드시 찾는다는 보장도 할 수 없지만 정수 및 혼합정수계획법, 불연속성 문제 등에 대해서는 이러한 알고리즘이 적절한 선택이 될 수 있다.
5.4.5 Algorithm Efficiency
지금까지 알고리즘의 효율성에 대해서 계산 속도와 같은 요소를 보았지만, 기존 관례에서는 주어진 크기의 문제를 해결하는 데 필요한 단계 수 또는 기본 연산 수로 알고리즘의 효율성을 추정한다.
→ 이러한 기준은 최악의 경우에 대한 성능을 기준으로 한 것. 그러나 최악의 상황에서 단계 수가 많다고 해서 실제에서 성능이 나쁘다는 것은 아님.
실무적으로 중요한 것은 일반적인 문제들에 대해 잘 작동하는지에 대한 여부이다.
ex. 심플렉스는 최적해를 찾는 데 몇 단계가 걸릴지에 대한 보장을 하지 못하지만, 실무적으로 굉장히 잘 작동한다(현실 문제들은 심플렉스 관점에서 최악의 형태가 대부분 아니기 때문).
그럼에도 불구하고 이론적으로 우월하다는 것은 실제 성능에서도 더 나은 결과로 이어지는 경우가 많다는 것. 따라서 문제 크기에 대해 다항시간(polynomial time)에 동작하는 알고리즘은 지수시간(exponential time)에 동작하는 알고리즘보다 선호된다.
즉, 문제 크기 n, 양의 정수 k에 대해 $O(n_k)$ 의 연산횟수를 가진 다항시간보다 $O(k_n)$ 횟수를 가진 지수시간이 훨씬 크다.
5.5 OPTIMIZATION DUALITY
5.4.2에서 봤던 KKT 조건의 라그랑주 승수 u, v는 최적화 이론 및 실제에서 특별한 역할을 하는데, 이들은 원래 최적화 문제(primal problem)와 매우 특정한 방식으로 관련된 특정 쌍대 최적화 문제에서의 변수이다.
기본 문제가 최소화 문제라면, 쌍대 문제는 최대화 문제가 되는 구조이며, 변수 수는 기본 문제의 제약식 수와 같으며, 반대도 동일하다.
쌍대성 이론은 다음과 같은 중요성을 가진다.
- 좋은 쌍대문제의 해는 원문제의 목적함수 값에 대한 경계를 계산하는 데 사용할 수 있으며, 이를 통해 원문제 해가 최적에 얼마나 가까운지 판단할 수 있다.
→ Dual value $\leq$ Primal value 가 성립. - 특정 볼록 최적화 문제에서는 쌍대문제의 최적값 = 원문제의 최적값 이 성립함.
- 쌍대문제는 원문제보다 수학적 또는 계산적으로 더 좋은 구조를 가지는데, 이를 통해 최적해를 계산하는 데 활용할 수 있음.
- 쌍대변수를 통해 원문제에 대한 민감도 분석을 수행할 수 있음. 원문제의 특정 제약식에 대응하는 쌍대변수는 그 제약식의 우변을 1단위 증가시켰을 때 최적 목적함수 값이 얼마나 변하는지를 나타낸다.
일반적인 최적화 원문제 P를 고려해보자.
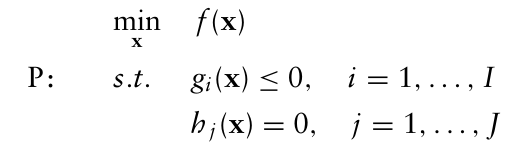
쌍대문제 D는 3단계로 구성된다.
- I개의 비음수 승수 $u_i$ 와 J개의 승수 $v_j$ 를 사용하여 제약조건을 목적함수에 포함시켜 라그랑지안 함수를 만든다.
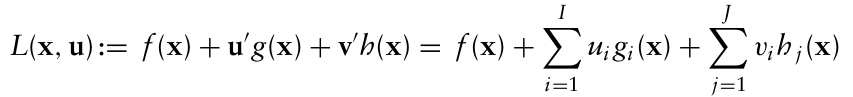
- 쌍대문제를 생성한다.
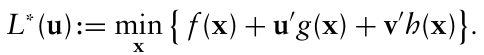
- 쌍대문제를 작성한다.
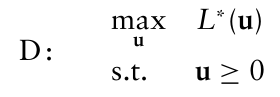

- 이러한 볼록문제의 예에서, 원문제의 유형(LP, QP, SOCP)는 쌍대문제에서도 그대로 유지된다(일반적인 비선형 최적화는 x).
5.6 MULTISTAGE OPTIMIZATION
우리는 종종 미래 여러 시점에 걸쳐 최적의 전략을 찾고자 할 때가 있다.
ex. 한 회사가 향후 몇 년 동안의 일련의 운영 결정을 고려해야 하는 경우
이러한 Multistage 프레임워크는 표준 최적화 수식을 통해 표현할 수 있지만, 어렵기도 하고 문제를 해결하는 데 가장 효율적인 알고리즘을 항상 사용할 수 있는 것은 아니다.
금융에서의 동적 의사결정 모델은 일반적으로 미래 현금 흐름을 표현하는 것을 포함하며, 이를 그래프로 시각화하는 것이 가장 이해하기 쉽다.
가로축에는 현금흐름이 발생하는 시간 시점을 표시한다. 각 시점마다 노드(node)를 사용하여 그 시점에서 동적 시스템이 가질 수 있는 서로 다른 상태(state) 또는 조건을 나타낸다. 이러한 모든 상태들의 집합을 상태공간(state space)이라고 한다.
의사결정자의 행동에 따라 다음 상태가 결정되며 특정 상태에서 도달 가능한 다른 상태들은 해당 상태와 연결되어 표현된다.
5.6.1 Finite State Space
두 개의 단순한 동적 시스템의 예시를 고려해보자.
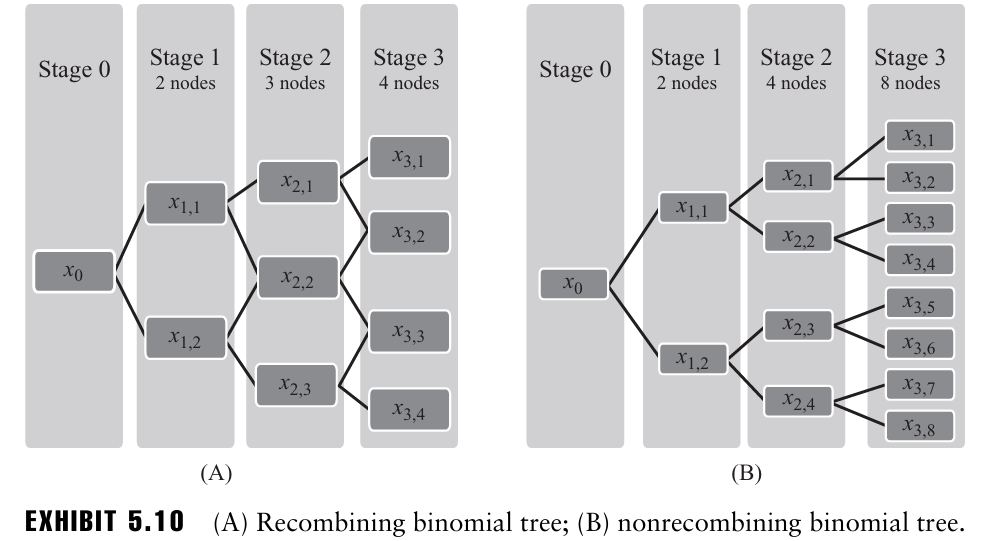
- 이 그래프들은 각 노드에서 2개의 가지가 뻗어 나오기 때문에 이항 트리(binomial trees) 또는 이항 격자(binomial lattices) 라고 부른다.
- 가지의 수는 특정 상태에서 의사결정자가 선택할 수 있는 옵션 수를 의미한다.
- A의 가지들은 다시 합쳐지지만 B의 가지들은 합쳐지지 않는데, A의 가지처럼 서로 합쳐지는 그래프를 recombining trees 또는 recombining lattices라고 부른다.
ex.
3년짜리 유전(oil well) 임대권을 구입했다고 가정해보자.
해당 유전의 추정 매장량은 600,000배럴이다.
선택할 수 있는 전략은 두가지로,
- 일반 채굴: 연간 100,000배럴 채굴
- 강화 채굴: 연간 200,000배럴 채굴
이때 시간 t에 강화 채굴 방법으로 $u_t$ 배럴을 채굴하면 $20 \cdot \frac{u_t^2}{x_t}$ 달러의 비용이 발생한다. 반면 일반 채굴의 비용은 $\frac{u_t^2}{x_t}$ 이다.
두 경우 모두 남은 매장량 $x_t$ 가 줄어들수록 채굴 비용은 증가한다.
유가의 기댓값은
- 1년차: 45달러
- 2년차: 30달러
- 3년차: 40달러
연간 할인율(discount factor)은 0.9이다.
두 채굴 방식 중 하나만 가능하다고 가정할 때 임대권에서 발생하는 이익의 현재가치를 최대화하는 최적의 전략은 무엇인가?
→ 한가지 접근 방식으로는, 각 연도의 유가를 보고 각 전략의 수익과 비용을 계산하여 그 해에 가장 높은 이익을 주는 전략을 선택하는 것.
그러나 각 연도의 이익이 현재의 매장량에 의존하기 때문에 그렇게 단순하게 해결되지 않는다.
현재 가격이 $p_t$ 라고 했을 때, 전략 1의 이익은 $p_t \cdot 100,000 - \frac{u_t^2}{x_t}$, 전략 2의 이익은 $p_t \cdot 200,000 - 20 \cdot \frac{u_t^2}{x_t}$
→ 각 연도의 최적 의사결정은 서로 독립적이지 않기 때문에 각 해를 개별적으로 분석할 수 없음.
이러한 동적 시스템에서 state를 어떻게 정의하는 것이 적절한가?
→ state는 특정 시점에서 시스템에 대한 모든 정보를 포함해야함.
따라서 시간 t에서의 현재 매장량 $x_t$ 가 적절한 상태변수.
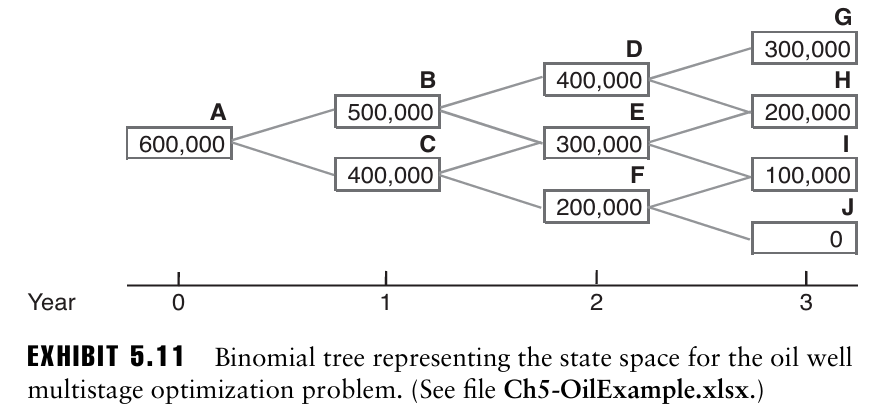
- 일반 채굴 방법을 선택하면($u_0 = 100,000$), 유전의 매장량은 100,000배럴 감소하고 1년차에 노트 B에 도달한다.
- 강화 채굴 방법을 선택하면 매장량은 200,000배럴 감소하고 1년차에 노트 C에 도달한다.
→ 이 트리는 recombining tree이다. A-B-E 와 A-C-E 모두 2년차에 노드 E에 도달함.
이 그래프에는 총 8개의 경로가 있으며, 최적 경로를 찾기 위해 각 경로에서 발생하는 이익의 현재가치를 계산한 후, 가장 큰 현재가치를 주는 경로를 선택할 수 있다.
→ 문제는 실제에서는 기간이 훨씬 더 길고 가능한 state도 더 많아지게 될 경우 계산비용이 너무 커짐.
문제를 최소한의 계산과 저장공간으로 해결하는 방법은 오른쪽 끝 최종 노드들부터 시작해서 거꾸로 계산하는 것이다. 각 노드에서 최적 경로 하나만 저장하고 다른 경로들은 버린다.
이러한 순차적 최적화 방법을 동적계획법(Dynamic Programming)이라고 한다.
중간 단계에서 비최적 선택을 한 상태에서 전체 최적해에 도달하는 것은 불가능하기 때문에 현재 상태에서 도달 가능한 각 상태에 대해 최적 선택만 추적하면 된다.
이를 유전 문제에 적용하면, 노드 G,H,I,J에서는 임대가 종료되었기 때문에 이익이 발생하지 않는다. 2년차 초에 D,E,F 중 하나에 있을 수 있는데 만약 D에 있다면 일반 방법을 사용했을 때 이익은 $40 \cdot 100,000-100,000^2/400,000 = 3,975,000$ 이며, 강화 방법을 사용했을 때 이익은 $40 \cdot 200,000-20 \cdot 200,000^2/400,000 = 6,000,000$ 으로 더 높은 이익을 준다. 따라서 노드 D에서는 강화 방법을 사용하는 것이 좋다.
E,F에 대해서도 계산을 해보면 각 5,333,333 과 4,000,000의 이익을 주는 강화 방법을 사용하는 것이 최적 전략이 된다.
다음으로 1년 초에서 B와 C 노드에 대해 고려하자.
- 노드 B 일반: $30 \cdot 100,000 - 100,000^2/500,000 = 2,980,000$
→ 노드 D의 이익을 고려한 총 이익은 2,980,000 + 0.9 \cdot 6,000,000 - 노드 B 강화: 4,400,000
→ 노드 E의 이익을 고려한 총 이익은 4,400,000 + 0.9 \cdot 5,333,333
따라서 노드 B에서 강화 방법을 선택하는 것이 최적의 전략이다.
C, A 노드도 유사한 방식으로 계산하면 각 시점에서 최적의 전략만 기록할 수 있다.
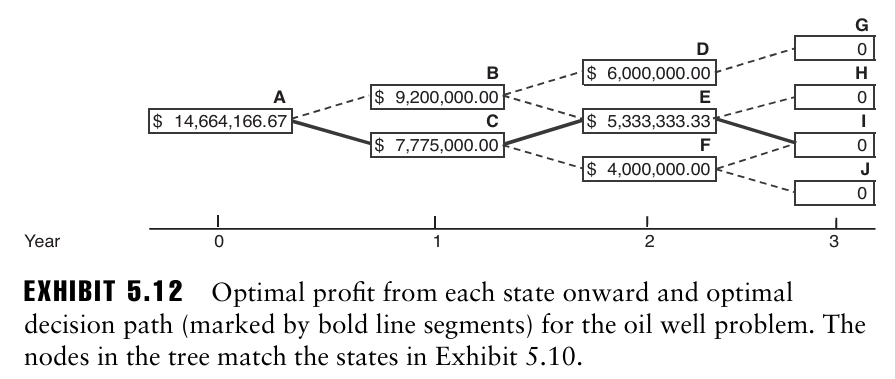
총 이익의 현재가치가 가장 높은 경로는 A-C-E-I이다.
※ 노드 A에서 노드 B, C의 최적의 미래 이익을 본다면 노드 B로 가고 싶겠지만 1년차의 유가가 충분히 높기 때문에 전체적으로 보면 노드 C로 가는 것이 최적이 된다. 따라서 미래 가치만 비교하면 최적 전략을 선택하지 못 할 수 있다.
Standard Notation Used in Dynamic Programming
동적계획법에서의 몇 가지 표준 notation이 존재한다.
각 상태에서 필요한 모든 정보를 요약하는 변수를 상태변수(state variable)이라고 하며, 위 예제에서는 시간 t에 이용 가능한 유전량인 $x_t$ 가 상태변수였다.
통제변수 또는 정책변수(control or policy variable)는 사용자의 결정을 의미하며 위 예제에서는 채굴할 유전량인 $u_t$ 로 설정했다.
상태변수는 통제변수와 이전기간 상태변수에 대한 함수로 표현되며, 각 단계마다 전이 방정식에 의해 갱신된다.
$x_{t+1} = x_t - u_t$
위 예제에서 총 단계 수는 T = 3 이었는데, 목표는 각 단계에서의 이익의 현재가치의 합이었기 때문에 목적함수를 다음과 같이 쓸 수 있다.
$\sum_{t=0}^{T-1} f_t(x_t,u_t)$
또한 어떤 특정 노드 이후부터 발생하는 보상을 가치 함수(value function)이라고 부르며, V로 표기한다.
동적계획법 알고리즘은
- 현재 단계에서의 즉각적 보상
- 그리고 그 이후 단계들에서 얻을 수 있는 최적 보상
의 합을 최대화하며, 재귀식은 다음과 같이 쓸 수 있다.
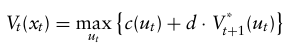
이를 위 예제에서 사용하면,
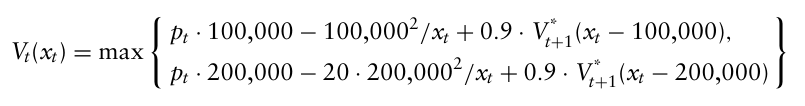
가치함수의 실제 값을 계산하기 위해선 동적계획법 알고리즘에 경계조건이 필요하다.
경계조건은 끝 지점에서의 값에 대한 정보를 제공하는데, 위 예제에서는 3년이 지나면 임대 계약이 만료되기에 3년이 시작되는 시점에서 실현 가능한 이익은 0이라는 것을 알고 있었다.
→ 이 사실로 인해 T = 3 에서의 가치함수를 계산할 수 있었으며 이를 바탕으로 backward 연산이 가능했다.
On the Relationship between Dynamic Programming and Classical Optimization Formulations
이 섹션에서는 5.2절 및 5.3절에서 논의된 고전적 최적화 공식들 간의 관계를 설명하기 위해 유전 예제를 표준 최적화 문제로 표현한다.
각 단계에서 최적 매장량을 저장할 결정변수 $x_0, x_1, x_2$ 를 도입한다. 이후 각 단계에서 최적 채굴량을 결정할 결정변수 $u_0, u_1, u_2$ 를 도입한다.
→ 이때 결정변수 u는 discrete한 값으로, 10만 또는 20만 배럴만 채굴할 수 있음.
또한 $z_0, z_1, z_2$ 를 이진 변수로 설정하고 1이면 10만 배럴, 0이면 20만 배럴을 채굴하도록 한다.
그런 다음 정책 변수(policy variables) $u_0, u_1, u_2$ 를 이진변수 z와 연결하여 다음과 같이 나타낼 수 있다.
$u_t = 100,000 \cdot z_t + 200,000(1-z_t), \, t=0,1,2$
마지막으로 각 단계의 석유 매장량 $x_t$ 와 정책 변수 $u_t$ 사이의 관계를 명시적으로 표현하면 다음과 같다.
$x_t = x_{t-1} - u_{t-1}, \, t=1,2$
즉 각 단계에서의 최적 매장량은 이전 단계에서 보유하고 있던 양에서 채굴한 최적량을 빼서 계산한다.
목적함수는 세 단계 전체에 걸친 총이익을 최대화하는 것으로 공식화하면 다음과 같다.
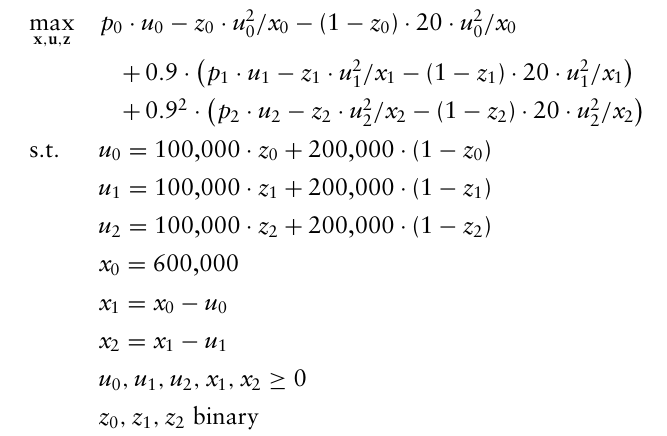
이렇게 얻은 최적해는 다음과 같으며, 이는 위에서 직접 풀었 때 얻은 해와 동일하다.
5.6.2 Infinite State Space
금융 분야에 적용해보면, 무한 상태 공간을 가진 동적계획법을 다뤄야 하는 경우가 존재한다.
ex. 여러 기간에 걸쳐 관리되는 투자에서 시스템의 상태가 현재 보유 자산에 의해 결정되고 자산에 투자된 비율이 정책변수가 된다면 가능한 상태의 수(각 시점에서 포트폴리오 내 자산 비율의 가능한 조합)는 무한일 수 있다.
이 경우 동적계획법을 시각화하는 것이 어렵고, 위 예제처럼 각 상태의 최적 전략을 계산할 수 없게 된다. 최선의 방법은 각 상태에서의 정보를 기준으로 최적 전략을 나타내는 표현식을 찾는것.
하지만 이 또한 항상 가능한 것은 아니며 때로는 근사값을 사용하는 경우도 존재한다.
유전 예제를 변형해보자. 3년 동안 유전 임대권을 구매했고, 예상 매장량은 60만 배럴이며, 가격, 할인율 모두 동일한 상황에서 원하는 만큼 석유를 채굴할 수 있으며 비용은 $20 \cdot u_t^2/x_t$ 이다. 가장 적절한 상태변수는 t시점의 잔여 매장량임을 알 수 있지만, 이번에는 각 단계마다 가능한 상태의 수가 무한히 많아져서 이항 트리를 더이상 그릴 수 없다.
다행히도, 동적계획법 재귀(dynamic programming recursion)를 사용하여 이 문제를 풀 수 있는데, 2년차의 시작지점에 있다고 가정했을 때 어떤 상태 $x_2$ 에 대한 가치함수 $V_2(x_2)$ 는 다음과 같다.
$V_2(x_2) = \max\limits_{u_2} ( p_2 u_2 - 20 \frac{u_2^2}{x_2} )$
이 문제는 비제약 최적화 문제로, 이차함수이기 때문에 최댓값은 도함수가 0이 되는 지점에서 발생한다.
$u_2^{*} = p_2 \cdot x_2/40$
다음으로 1년차에서의 최적 채굴량을 구해보면,
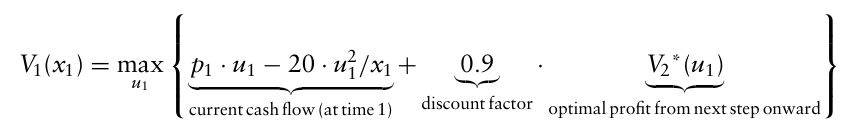
이때 2년차 최적화에서 얻은 $u_2^{*}$ 로 $V_2(x_2)$ 에 대입하여 $V_2^* (x_2)$ 를 구할 수 있다.
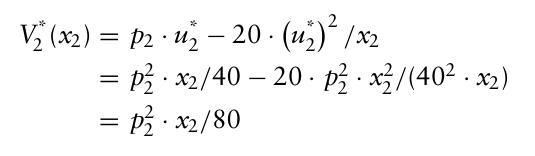
따라서 1년차의 최적 이익은 다음과 같다.
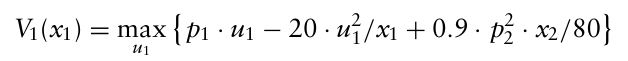
$x_{t+1} = x_t + u_t$ 가 성립하므로, $V_1(x_1)$ 의 $x_2$ 을 $x_1 - u_1$ 로 대체할 수 있다.
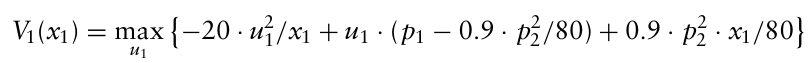
이후 $u_1$ 에 대해 도함수를 구하여 최대값을 찾으면 다음과 같다.
$u_1^* = (p_1 - 0.9 \cdot p_2^2/80) \cdot x_1/40$
→ $p_1, p_2$ 는 각각 30, 40 이므로 대입하면,
$u_1^* = (12/40) \cdot x_1 = 0.3 \cdot x_1$, 이를 가치함수에 대입하면 $V_1(x_1) = 19.8x_1$
0년차에서의 최적 전략 평가를 동일한 방식으로 진행하면,
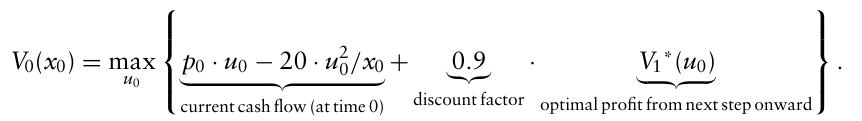
$x_1 = x_0 - u_0$
$V_1^* (u_0) = 19.8(x_0 - u_0)$
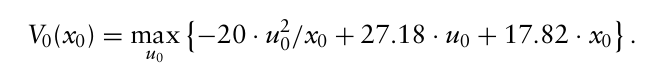
이때 $p_0 = 45$ . 따라서 최적해는 $u_0^* = 0.6795x_0$
→ $x_0 = 600,000$ 이므로 $u_0^* = 407,700$
최종적으로 3년에 걸친 최적 총 이익은 다음과 같다.
$V_0(x_0) = -20 \cdot 407,700^2 / 600,000 + 27.18 \cdot 407,700 + 17.82 \cdot 600,000 = 16,232,643$
5.6.3 Steps in Formulating Multistage Optimization Problems
5.6.1절과 5.6.2절의 동적계획법 예시를 통해 동적계획법 알고리즘을 구성할 때 우리가 진행해야 할 일반적인 단계에 대해서 살펴보았다.
이는 다음과 같은 정보를 제공한다.
- 해를 여러 단계에 걸쳐 발생하는 일련의 결정으로 생각하고, 총 비용을 개별 결정의 비용 및 보상의 합으로 표현하라.
- 시스템의 상태를 정의할 때, 과거의 모든 관련 정보를 요약할 수 있도록 정의하라.
- 어떤 상태 전이가 가능한지 결정하고, 그 상태들을 연결하라. 한 상태로 이동할 때 발생하는 비용 및 보상은 그 전이를 유발한 의사결정의 비용 및 보상과 같아야 한다.
- 마지막 상태에서 시작하여 거슬러 올라가면서 최적 비용 및 보상을 재귀적으로 계산하는 식을 작성하라.
결국 가장 중요한 것은 좋은 상태공간(state space) 정의를 찾는 것.
→ 다음 상태로의 전이에서 발생하는 비용/보상이 현재 상태와 의사결졍 변수에만 의존하고 가치함수 역시 현재 상태와 의사결졍 변수에만 의존해야함.