Review: Autoencoder asset pricing models
해당 게시글은 Gu et al,(2020)의 “Autoencoder asset pricing models” 논문을 리뷰한 글입니다. 본 게시물에서 인용한 논문 및 자료에 대한 상세 정보는 아래의 링크를 통해 확인하실 수 있습니다.
Gu et al,(2020)
1. Introduction
최근 자산 가격 문헌들 중에서 특성 기반 자산 수익률 예측에 대한 이상현상(anomaly) 관점을 제시하는 연구가 많이 등장하는데, 이상현상 관점에서는 특정 자산 특성이 기존 리스크 팩터로 설명되지 않는 추가적인 평균수익(알파)을 예측할 수 있다고 주장한다.
반면 Kelly, Pruitt, Su(KPS, 2019)는 이러한 이상현상이 관측 불가능하며, 특성들은 시간에 따라 변하는 리스크팩터 노출을 대리하고 있다는 것을 보여준다. 또한 이 특성들은 팩터 노출을 설명하는 힘을 통제하고 나면 추가적인 이상수익 예측력을 거의 갖지 못한다고 주장한다.
즉 특성은 리스크 팩터 노출에 대한 보상을 파악하는 데 도움을 주기 때문에 수익률을 예측하는 것처럼 보이는 것이다.
KPS가 제안한 자산 가격 모델은 개별 수익률 $r_{i,t}$ 가 K-팩터 구조를 가진다고 가정한다.
$r_{i,t} = \beta(z_{i,t-1})’f_t + u_{i,t}$
이때 팩터 $f_t$ 는 latent factor이며, K by 1 조건부 팩터 노출 $\beta(z_{i,t-1})$ 는 자산 특성 P by 1 벡터 $z_{i,t-1}$ 의 함수이다.
KPS에서는 P개의 특성에서 K개의 베타로의 매핑이 선형이라는 가정을 한다.
$\beta(z_{i,t-1})’ = z_{i,t-1}’\Gamma$
이러한 선형성 가정은 편리하지만 명확한 이론적 또는 직관적 정당화가 존재하진 않는다. 반면 이 가정이 위배될 것으로 예상되는 많은 이유가 존재하는데, 본질적으로 모든 주요 이론적 자산 가격 책정 모델은 상태변수의 함수로서 수익률이 비선형적인 관계를 가짐을 예측한다.
→ Campbell and Cochrane(1999), Bansal and Yaron(2004)
또한 팩터 위험노출이 복잡한 움직임을 가진다고 예측하며(Santos and Veronesi(2004)), 비선형 모형을 선형으로 근사할 경우 주식 프리미엄의 크기나 수익률 예측력에 대해 상당한 오차가 발생할 수 있음을 보인다(Pohl et al., (2018)).
따라서 본 논문에서는 KPS의 식을 오토인코더(Autoencoder) 계열의 모형을 사용하여 일반화한다.
오토인코더는 머신러닝 분야에서 널리 사용되는 차원축소 모델로, PCA의 비선형 신경망 대응 모형으로 볼 수 있다. 이는 비지도 학습 방법으로, 자산수익률 전체 패널을 오직 수익률 데이터 자체만을 입력으로 사용하여 모델링하고자 한다.
PCA와 오토인코더의 통계적 핵심은 병목(bottleneck) 구조로, 이는 수익률 데이터를 간결하게 표현하도록 강제한다.
PCA의 병목은 N개의 개별 수익률을 K개의 팩터로 선형 매핑하는 것이고, 오토인코더는 신경망을 통해 이를 비선형 매핑으로 확장한다.
하지만 두 모델 모두 기본 형태에서는 공변량 정보를 차원축소에 활용하지 않는데, KPS는 도구화된(instrumented) PCA, 즉 IPCA를 제안하면서 공변량 정보를 차원축소 과정에 활용했지만, 이는 여전히 선형 모형 구조에 의존한다고 할 수 있다.
본 논문에서는 개별 주식 수익률을 위한 새로운 조건부 오토인코더 모델을 소개한다. 이 모델은 IPCA처럼 공변량을 사용하며 신경망 기반 수익률 압축으로 저차원 팩터 집합을 만들어내며, 주식의 특성 공변량이 팩터 노출에 비선형적인 영향을 미치도록 한다.
또한 오토인코더 구조를 설계하는 데 있어서 팩터가 포트폴리오로 해석될 수 있도록 한다.
미국의 60년간 개별 주식 수익률에 대한 실증 분석 결과, 본 논문의 오토인코더 모델이 Fama-French 모델 뿐만 아니라 KPS의 IPCA 모델보다 우월하다는 결과를 보인다.
모델 비교는 두가지 통계적 기준에 기반하며, 자산 집합의 위험성, 즉 공동 수익률의 변동을 설명하는 모델의 능력을 측정하는 total $R^2$ 과 자산 간 위험 보상 차이를 모델이 설명할 수 있는 능력을 측정하는 Predictive $R^2$ 로 평가한다.
결과적으로 3팩터 모델로 동일하게 맞추었을 때, 오토인코더, IPCA, FF 3 팩터 모델의 월별 total $R^2$ 는 각각 12.6%, 13.3%, 3.4% 이며 Predictive $R^2$ 는 각각 0.5%, 0.23% 그리고 FF3 모델의 경우 음수임을 발견했다.
또한 경제적 측면에서도 모델 간의 상대적 성과를 비교한다. 각 모델의 Out-of-sample 주식 수익률 예측에 따라 정렬된 롱숏 포트폴리오를 형성하여 동일가중했을 때 연간 샤프비율은 각각 2.16, 1.26, -0.4 를 기록한다. 가치가중 기준으로는 각 0.92, 0.59, -0.69 를 기록한다.
즉 본 논문에서 제시한 조건부 오토인코더 모델이 다른 기존 팩터 모델들을 큰 폭으로 능가하며, 이는 금융 시장의 위험과 수익의 횡단면을 분석하기 위해 기계학습과 같은 고차원 통계 방법을 사용하는 문헌들에 기여한다.
여기서는 전통적인 오토인코더를 확장하여 조건부 베타를 정할 때 신경망을 넣는다. 이를 통해 기업 특성들이 비선형적 관계로 작용하면서 위험노출을 결정할 수 있으며, KPS의 IPCA 베타를 일반화한 것이라고 할 수 있다.
또한 또다른 선행 연구인 Kozak et al.,(2018) 에서 진행한 PCA 기반 이상현상 포트폴리오 추출 방식의 단점이었던 테스트 자산의 한계(개별 주식의 경우에는 설명력이 낮았음)를 가지지 않는다는 점도 본 논문이 제시한 모델의 장점이다.
※ Kozak et al.,(2018)
이상현상 기준으로 나눈 포트폴리오들로부터 PCA를 적용해 만든 팩터로 팩터모델을 구성한 연구.
나아가, 조건부 오토인코더 모델이 확률적 할인요인(SDF)의 비모수적 모형과 동등한 구조이며, 무차익 가격결정이라는 경제적 제약을 만족함을 보인다.
2. Methodology
이 섹션에서는 먼저 표준 오토인코더를 설명한 후, 공변량을 조건 정보로 활용하는 조건부 오토인코더를 소개한다.
2.1. Standard autoencoder
오토인코더는 출력이 입력 변수를 근사하도록 하는 특별한 신경망으로, 입력변수는 은닉층의 소수 뉴런을 거쳐 입력의 압축된 표현(인코딩)을 형성하며, 이는 이후 출력층으로 매핑(디코딩)된다. 입력 외에는 다른 변수가 이 모델에서 사용되지 않기 때문에 오토인코더는 비지도 학습 모델이다.
각 층 $l = 1,…,L$ 의 뉴런 수를 $K^{(l)}$ 로 나타내며, 층 $l$ 에서 뉴런 k의 출력을 $r_k^{(l)}$ , 해당 층의 모든 출력 벡터를 $r^{(l)} = (r_1^{(l)},…,r_{K^{(l)}}^{(l)})’$ 으로 정의한다.
이전 층의 입력은 다음 층으로 전달되기 전에 비선형 활성화 함수 g(.)에 따라 변환된다. 네트워크를 초기화하기 위해 입력층은 수익률의 횡단면을 사용하며 $r(0) = (r_1,…,r_N)’$ 으로 나타난다. 따라서 L개의 은닉층을 가진 신경망 모델에서, 층 $l$ 은 다음의 재귀 공식으로 표현될 수 있다.
$r^{(l)} = g(b^{(l-1)} + W^{(l-1)}r^{(l-1)})$
W는 가중치 매개변수 행렬, b는 편향 매개변수 벡터이다. 본 논문에서는 비선형 활성화 함수로 ReLU를 사용하며, 오토인코더의 최종 출력은 다음과 같다.
$G(r,b,W) = b^{(L)} + W^{(L)}r^{(L)}$
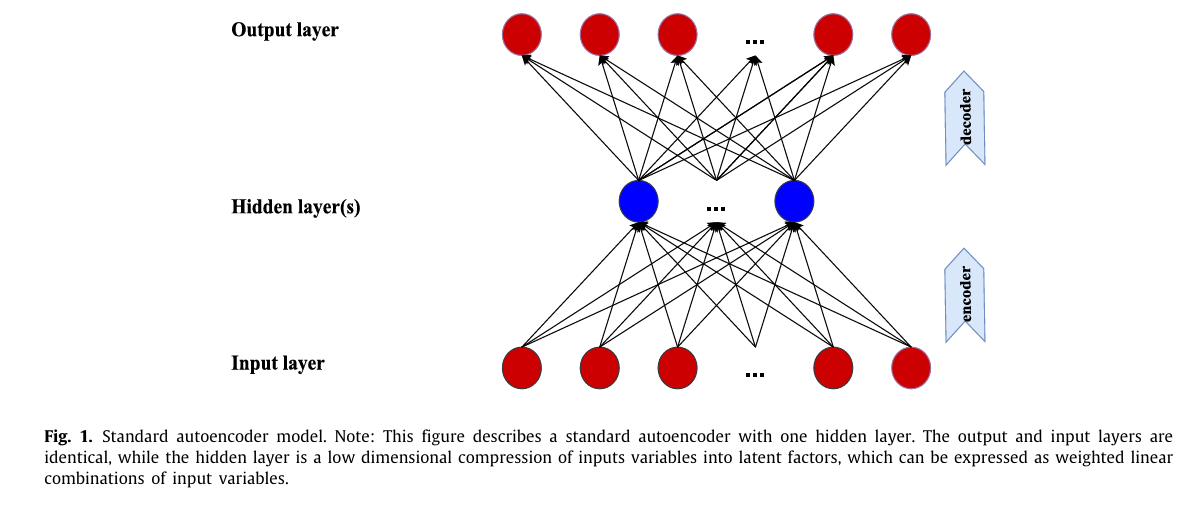
그림 1은 단일 은닉층을 가진 간단한 선형 오토인코더의 구조이다.
2.1.1. Static linear factor models as a special case
오토인코더의 목적은 입력에 대해 더 적은 수의 차원을 가진 표현을 학습시키는 것이다. 따라서 PCA와 동일한 목표를 가지지만 입력의 비선형 압축이 허용된다는 점에서 더 유연한 모델이라고 할 수 있다.
이 섹션에서는 오토인코더와 PCA 간의 연결에 대해 논의한다. 금융 문헌에서 자산 수익률을 가장 일반적으로 연구하는 모델들은 정적 로딩을 가지는 linear latent factor를 가정한다.
$r_t = \beta f_t + u_t$
$R = \beta F + U$
(U: idiosyncratic errors)
이러한 팩터 모델은 수익의 공분산 행렬에 대한 PCA로 추정될 수 있다. 시간 평균이 제거된 수익을 특이값 분해(SVD)를 통해 팩터와 팩터 로딩의 추정치를 얻을 수 있다.
$\bar R = \hat P Λ \hat Q + \hat U$
여기서 $\hat P$ 와 $\hat Q$ 는 각각 좌측과 우측 특이벡터의 N by K, K by T 행렬이며, U는 N by T 잔차 행렬이다.
보다 구체적으로, K개의 뉴런을 가진 단일층 선형 오토인코더는 다음과 같다.
$r_t = b^{(1)} + W^{(1)}\bigl(b^{(0)} + W^{(0)} r_t\bigr) + u_t$
이후 모델은 다음의 최적화 문제를 해결함으로써 파라미터를 추정한다.
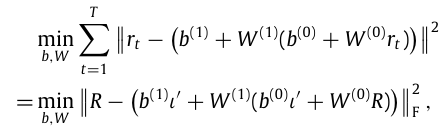
(ι: 모든 성분이 1인 T by 1 벡터)
※ Proposition 1.
$\hat{W}^{(1)} = \hat{P}_A,\; \hat{W}^{(0)} = (\hat{W}^{(1)\prime}\hat{W}^{(1)})^{-1}\hat{W}^{(1)\prime},\; \hat{b}^{(1)} = \bar{r} - \hat{W}^{(1)}\hat{b}^{(0)} - \hat{W}^{(1)}\hat{W}^{(0)}\bar{r},\; \hat{b}^{(0)} = a.$
여기서 A는 임의의 K by K 비특이 행렬이고, a는 상수 스칼라, $\bar r$ 은 $r_t$ 의 샘플 평균, $\hat P$ 는 좌측 특이벡터로 이루어진 행렬를 의미한다.
결과적으로 Proposition 1은 K개의 뉴런을 가진 은닉층의 선형 오토인코더가 K개의 잠재적인 팩터를 가지는 linear factor model임을 보여준다. 추정된 팩터 로딩은 $\hat W^{(1)}$ 이고 추정된 팩터는 $\hat W^{(0)}R$ 이다.
이는 PCA에서의 $\hat P$ , $\hat Q$ 와 동일한 공간을 span 하며, 오토인코더는 비선형 변환 계층을 통한 차원축소가 가능하므로 linear factor model보다 더 일반적이라고 할 수 있다.
2.2. Extending the autoencoder model to include covariates
기존의 정적인 linear factor model은 한계점이 다수 존재하는데, 자산 수익률의 분포가 시간에 따라 크게 변하기 때문이다. 정적인 팩터모델이 이러한 변화에 영향을 주는 다양한 정보를 반영하지 못한다.
KPS는 팩터 로딩 추정 시에 자산별 특성을 포함시키면 성과개선이 나타난다는 것을 보여주었는데, 팩터 로딩 추정 뿐만 아니라 latent factor의 추정도 간접적으로 개선되었음을 보였다.
큰 틀에서 KPS의 모델은 두개의 선형 모델을 결합한 형태로,
- latent factor에 대한 선형 모델
- 조건부 베타(conditional betas)에 대한 선형 모델
반면, 표준 오토인코더는 차원축소에는 매우 강력하지만 팩터 구조를 식별할 때 조건 변수들을 사용하지 않고 오로지 수익률 데이터만 사용해야 한다는 PCA와 동일한 한계점을 지닌다.
따라서 본 논문에서는 이러한 한계를 극복하기 위해 표준 오토인코더를 확장하여 자산의 특성을 포함하는 새로운 신경망 구조를 설계한다.
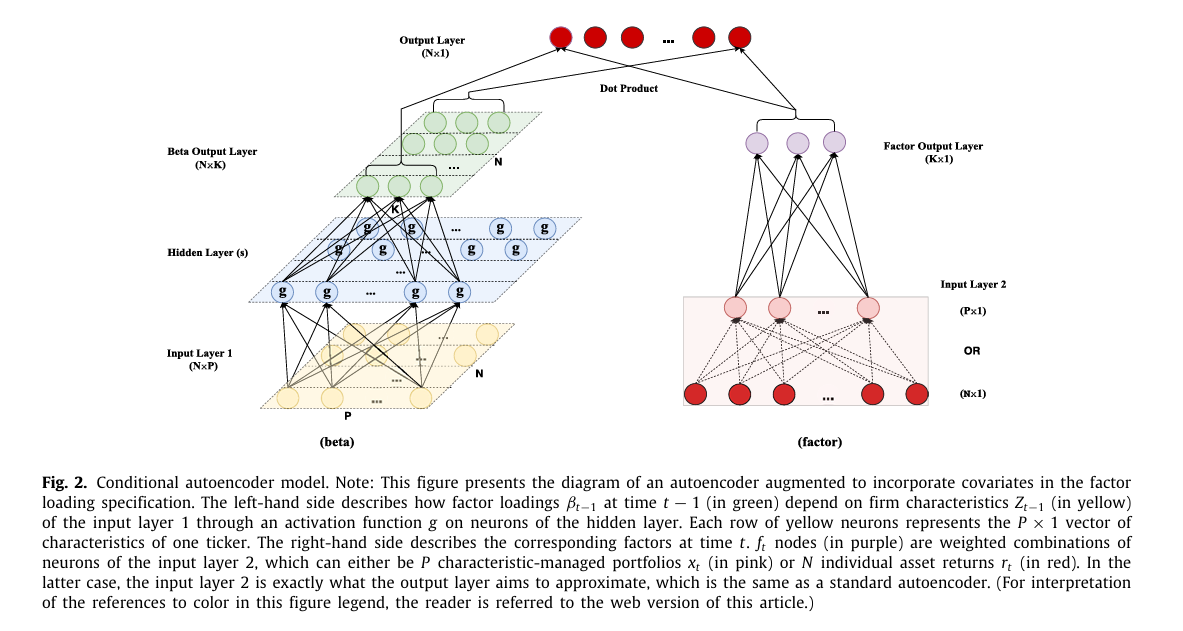
그림 2는 본 논문에서 제시하는 조건부 오토인코더(conditional autoencoder)의 기본 구조이다.
네트워크의 왼쪽 부분은 팩터 로딩을 자산 특성의 비선형 함수로 모델링하며, 오른쪽 네트워크는 팩터를 개별 주식 수익률의 포트폴리오로 모델링한다.
최종적으로 해당 모델의 상위 수준에서의 수학적 표현은 다음과 같다.
$r_{i,t} = \beta(z_{i,t-1})’f_t + u_{i,t}$
조건부 오토인코더와 IPCA의 주요 차이점은 조건부 베타의 공식화에 있다. 조건부 오토인코더에서는 K by 1 벡터 $\beta_{i,t-1}$ 를 과거 기업 특성 $z_{i,t-1}$ 에 대한 신경망 모델로 지정한다.
왼쪽 네트워크 구조인 비선형 베타 함수에 대한 재귀 공식은 다음과 같다.
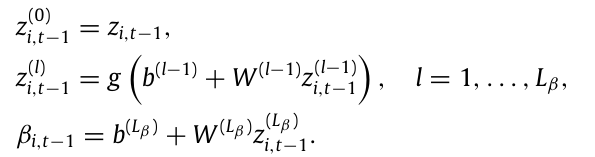
이 네트워크는 N by K 인 베타 행렬을 출력한다.
오른쪽 네트워크의 팩터를 정의하기 위한 표준 오토인코더 구조이다. 팩터를 계산하는 재귀 공식은 다음과 같다.
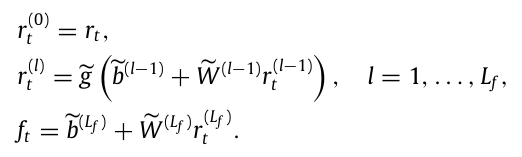
결과적으로 최종 출력층에서 최종 K개의 팩터 집합을 설명한다.
본 논문에서는 팩터 네트워크에 대해 단일 선형층( $L_f = 1$ )을 가정하는데, 이 구조가 팩터의 경제적인 해석을 유지할 수 있기 때문이다(팩터는 주식 수익률의 선형 결합으로 이루어진 포트폴리오이기 때문에).
최종적으로 N by K 의 베타 행렬과 K by 1 의 latent factor를 곱하여 각 개별 자산 수익률에 대한 예측값을 생성한다.
팩터 네트워크에서 개별 주식 수익률 전체를 사용하는 것은 두 가지 큰 어려움이 존재하는데, 먼저 표본의 개별 기업 수가 약 3만개로, 팩터 네트워크의 가중치 파라미터 수가 매우 커질 수 있는 반면, 데이터의 시계열 관측치는 약 720개에 불과하다. 또한 패널 데이터가 매우 불균형한데, 어떤 달에는 평균적으로 약 6000개 주식만 관측될 정도로 결측치가 많기 때문에 대부분의 주식별 가중치 파라미터는 매우 적은 시계열 관측치로 추정되게 된다.
따라서 본 논문에서는 모델의 계산 비용을 줄이기 위해 전체 주식 수익률 횡단면을 네트워크의 입력값으로 사용하는 대신, 특정 포트폴리오 집합을 사용하여 네트워크를 초기화한다.
$x_t = (Z_{t-1}’ Z_{t-1})^{-1} Z_{t-1} r_t$
이는 주식 특성을 기반으로 동적으로 재조정되는 포트폴리오 집합으로, $x_t$ 의 j번째 요소는 j번째 특성을 기준으로 주식을 정렬하여 구성된 롱숏 포트폴리오 수익률과 유사하다.
이를 통해 데이터의 사전 축소가 가능하며, 이는 N개의 수익률 $r_t$ 를 P개의 뉴런 $x_t$ 로 동적으로 축소하는 초기 레이어를 팩터 신경망에 추가하는 것이라고 볼 수 있다.
또한 이러한 초기 축소 방법은 패널 불완정성 문제를 우회할 수 있으며, 팩터 오토인코더를 특성 관리 포트폴리오에 대한 금융 문헌들과 연결할 수 있다.
2.2.1. Conditional linear factor models as a special case
오토인코더는 정적 선형 팩터 모델을 포함할 뿐만 아니라, KPS가 제시한 IPCA 팩터 모델 또한 포함한다.
KPS의 IPCA는 다음과 같은 최적화 문제를 해결한다.
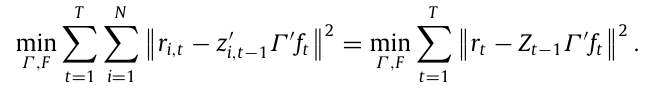
조건부 오토인코더의 단순 버전을 고려해보면, $\beta_{i,t}’ = Z_{t-1}W_0’$ 이고 $f_t = W_1x_t$ 이므로 추정 목적함수는 다음과 같다.
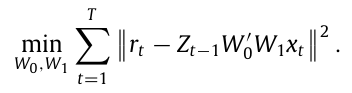
※ Proposition 2
$Z_t’Z_t = \sum$ 가 상수 행렬일 경우 위의 두 최적화의 해는 동일하다.
상수가 아닌 일반적인 경우에는 두 추정량이 유사하긴 하지만 동일하진 않다.
따라서 두 모델의 실증적인 성능이 유사하다는 것을 알 수 있다.
2.3. Regularized autoencoder learning
오토인코더는 신경망 모델과 마찬가지로 기존의 linear factor model에 비해 많은 장점을 가지고 있다.
특히 신경망 모델의 높은 표현력은 데이터로부터 가장 정보성이 높은 피쳐를 유연하게 구성할 수 있도록 한다.
→ But, 그만큼 과적합이 발생할 가능성도 높아짐.
따라서 이러한 과적합을 완화하기 위해 실증분석에서 다양한 정규화(regularization) 기법을 폭넓게 활용하는 등의 여러 가지 방법을 적용한다.
2.3.1. Training, validation, and testing
데이터는 학습, 검증, 테스트로 구분하여 분석을 진행한다(이 섹션에서는 학습, 검증, 테스트 셋의 역할에 대한 기본적인 설명만 있기 때문에 생략).
2.3.2. Regularization techniques
과적합을 방지하기 위한 가장 흔한 방법으로, 더 간결한 모델을 위해 목적함수에 패널티를 추가한다.
이를 반영한 추정 목적함수는 다음과 같다.
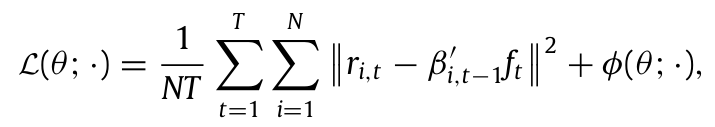
여기서 φ(θ)는 모델을 정규화하는 패널티 함수로, 본 논문에서는 LASSO(L1 penalty)를 사용했다.
추가적으로 early stopping을 도입하여 오버피팅의 가능성을 낮춰주었다.
마지막으로 앙상블을 활용하여 10개의 랜덤 시드로 신경망 추정을 초기화하고 모든 네트워크에서 도출된 추정 결과를 평균하여 모델 예측을 구성한다.
2.3.3. Optimization algorithms
신경망에서의 높은 비선형성 및 비볼록성, 많은 매개변수 구조는 단순한 무차별(brute force) 최적화로 해결하기 어렵게 만든다.
이를 해결하기 위해 일반적으로는 확률적 경사하강법(SGD)를 사용하며, 이는 표준 경사하강법이 매 반복(iteration)마다 전체 학습 데이터를 사용하여 gradient를 계산하는 것과는 달리 매 반복마다 데이터의 무작위 부분집합을 사용하여 gradient를 계산한다는 특징이 존재한다.
이는 정확도를 희생하지만 최적화 과정의 속도를 훨씬 끌어올릴 수 있다.
SGD의 하이퍼파라미터 중 하나로 learning rate가 있는데, 이는 경사하강 단계의 크기를 결정하며, gradient가 0에 가까워질수록 leargning rate를 점점 줄여야 한다(안그러면 gradient 계산에서 노이즈가 큰 영향을 미치게 됨).
→ 따라서 본 연구에서는 Adam을 활용.
마지막으로 batch normalization을 사용했는데, 이는 각 배치 사이즈만큼의 샘플에서 입력변수들의 변동성을 조절하기 위한 기법으로, 각 batch에서 각 은닉층에 대해 batch 입력값들의 횡단면 평균을 빼고 분산으로 표준퐈하여 internal covariate shift 현상을 완화한다.
※ internal covariate shift?
은닉층(hidden layer)의 입력 분포가 검증 데이터셋에서의 입력 분포와 서로 달라지는 현상. mini-batch 만큼의 데이터가 계속해서 분포가 달라지면 은닉층 입장에서는 입력 데이터의 분포가 계속해서 달라지는 것이기 때문에 학습이 제대로 이루어지지 않을 수 있음.
3. An empirical study of US equity
3.1. Data
CRSP에서 제공하는 3개의 주요 증권거래소(NYSE, AMEX, NASDAQ)에 상장된 모든 기업의 월별 개별 주식 수익률에서 개별 초과 수익을 계산하기 위해 무위험 이율을 대리하는 국채 이율을 사용한다.
표본은 1957.03 ~ 2016.12 까지 총 60년이며, 94개의 특성 데이터(61개는 연간 업데이트, 13개는 분기별, 20개는 월간 업데이트)를 사용한다.
또한 foward-looking bias를 피하기 위해 월별 특성값은 최대 한 달 지연, 분기별 값은 4개월 지연, 연간 값은 6개월 지연으로 가정하여 데이터를 과거 값으로 매칭한다.
결측치는 해당 특성의 횡단면 중앙값으로 대체하며, 모든 특성을 각 월 t마다 구간 (-1,1)으로 정규화한다.
추가적으로, 본 논문에서는 주가나 종목 코드에 기반한 필터 적용이나 금융회사 제외가 이루어지지 않는다. 해당 논문의 모델이 우수한 성능과 프레임워크의 풍부한 feature 집합 덕분으로, 샘플에 포함된 총 주식 수는 약 3만개이며, 월평균 주식 수는 6200개가 넘는다.
3.2. Models comparison set
실증분석에서는 PCA 기반 latent factor model을 비교한다.
이는 선형 함수 형태, 정적 베타, 추가 정보가 없는 모델이며 두번째 모델로는 IPCA를 비교한다. IPCA는 선형 함수 형태이지만 동적 베타와 추가 정보가 들어가 있는 모델이다.
그 다음으로, 논문에서 제안하는 조건부 오토인코더(CA) 를 비교한다. $CA_0$ 은 베타 네트워크와 팩터 네트워크가 모두 단일 선형 층이 사용된 모델으로 IPCA와 유사한 성격을 지닌다.
$CA_1$ 은 베타 네트워크에 32개의 뉴런이 있는 은닉층을 추가한 것이며, $CA_2$ 와 $CA_3$ 은 각각 베타 네트워크에 추가로 16개와 8개의 뉴런을 가진 은닉층을 추가한 것이다.
CA 모델은 모두 팩터 네트워크에는 단일 선형 층을 사용하며, 뉴런 수(팩터 개수)는 1부터 6까지로 제한된다.
또한 오토인코더 모델을 관측 가능한 팩터들을 활용하는 모델과 비교하며, 이를 FF 라고 부른다.
MKT → SMB → HML → UMD 순으로 가고, 5팩터 모델은 MKT, SMB, HML, CMA, RMW이며, 6팩터 모델은 UMD를 추가한 버전이다.
데이터는 1957-1986을 훈련, 1975-1986을 검증, 1987-2016을 테스트 셋으로 구분하며, 연 1회 모델을 업데이트한다. 이때 훈련 샘플을 1년씩 늘리고 검증 샘플은 동일하게 유지하되 최근 12개월을 포함하도록 한다.
3.3. Statistical performance evaluation
성과 지표는 KPS에서 정의한 Total R-square와 Predictive R-square를 사용한다.
Total R-square는 팩터모델 자체가 주식 수익률을 잘 설명하는지 나타내는 지표로, 다음과 같이 나타난다.
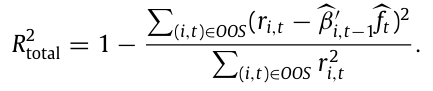
Predictive R-square는 미래 개별 초과 주식 수익률에 대한 모델의 예측 정확성을 평가하는 지표로, 훈련 기간 t-1까지의 $\hat f$ 의 평균을 $\hat \lambda_{t-1}$ 이라고 할 때, Predictive R-square는 다음과 같다.
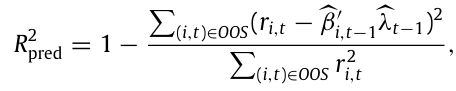
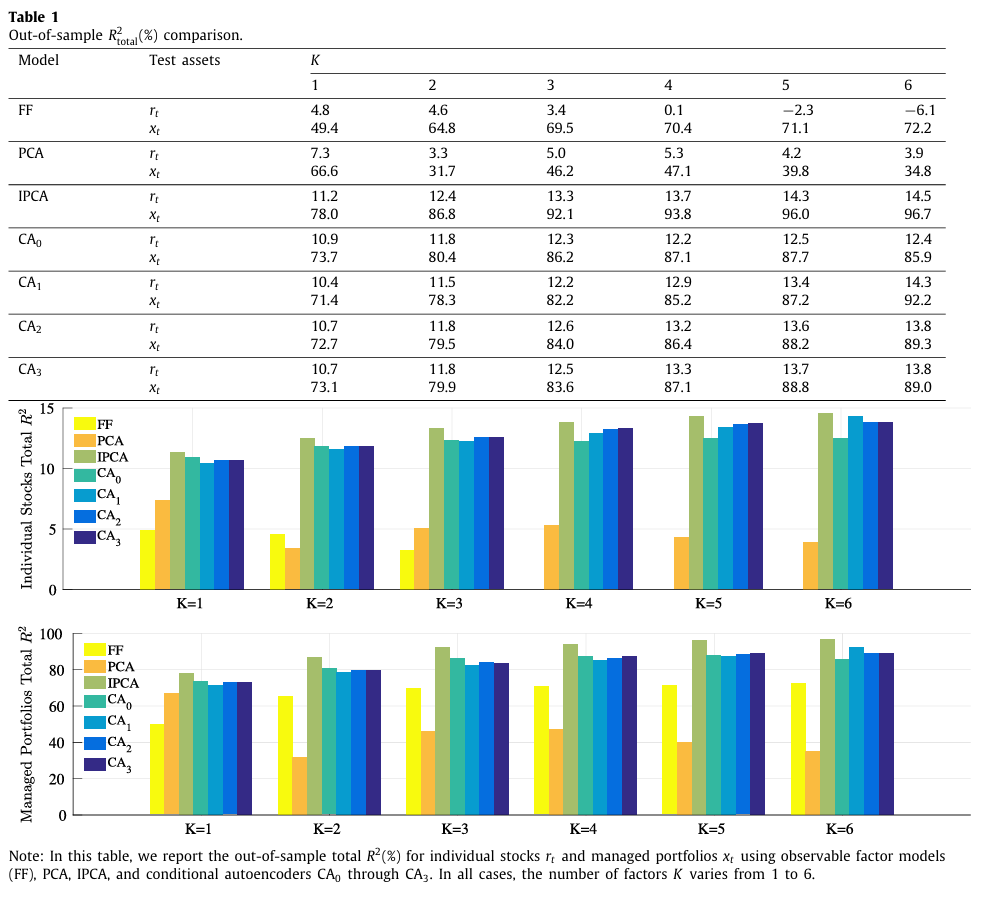
표 1은 개별 주식의 OOS Total R-square를 나타낸다.
- OOS에서 가장 설명력이 좋은 모델은 6팩터를 가지는 IPCA로, 14.5%의 값을 가진다.
- 그 다음으로 $CA_1$ 이 14.3%로 IPCA와 유사한 값을 가진다.
- 가장 성능이 낮은 모델은 FF 모델로, 이러한 결과가 나온 이유는 2가지로 설명할 수 있다.
- 모델 매개변수를 재추정하는 경우가 드문데, 개별 주식 수준에서는 베타가 시간에 따라 매우 변동이 심하기 때문에 정적 베타를 가지는 팩터 모델의 한계를 보인다.
- 본 논문에서는 기존 연구보다 훨씬 더 많은 주식 수를 사용하는데, 이는 기존에 관찰 가능한 팩터들로는 방대한 주식 유니버스를 설명하는 데 적합하지 않다는 것을 보인다.
- 놀라운 점은, KPS의 연구보다 데이터 세트가 훨씬 더 커졌음에도 불구하고 IPCA의 성능이 매우 견고하다는 것.
표 1에서는 개별 주식 이외에도 특성 포트폴리오(managed portfolios) $x_t$ 에 대한 Total R-square 값도 나타낸다. 여기서 포트폴리오는 개별 자산의 가중평균으로 이루어져 있기 때문에 모델 파라미터를 재추정하지 않고 그대로 input으로 넣는다.
- 이 포트폴리오는 개별 주식들의 집합이므로, 데이터의 비체계적 위험이 상당 부분 평균화되면서 Total R-square 값이 훨씬 더 높게 나타나는 경향이 존재한다.
- 여전히 IPCA가 최적의 설명력을 보이며 그다음으로 $CA_1$ 이 높은 설명력을 보인다.
- FF 모델의 성능은 개별 주식에 비해 개선되긴 했지만 여전히 IPCA 및 CA에 비해 낮은 설명력을 보인다.
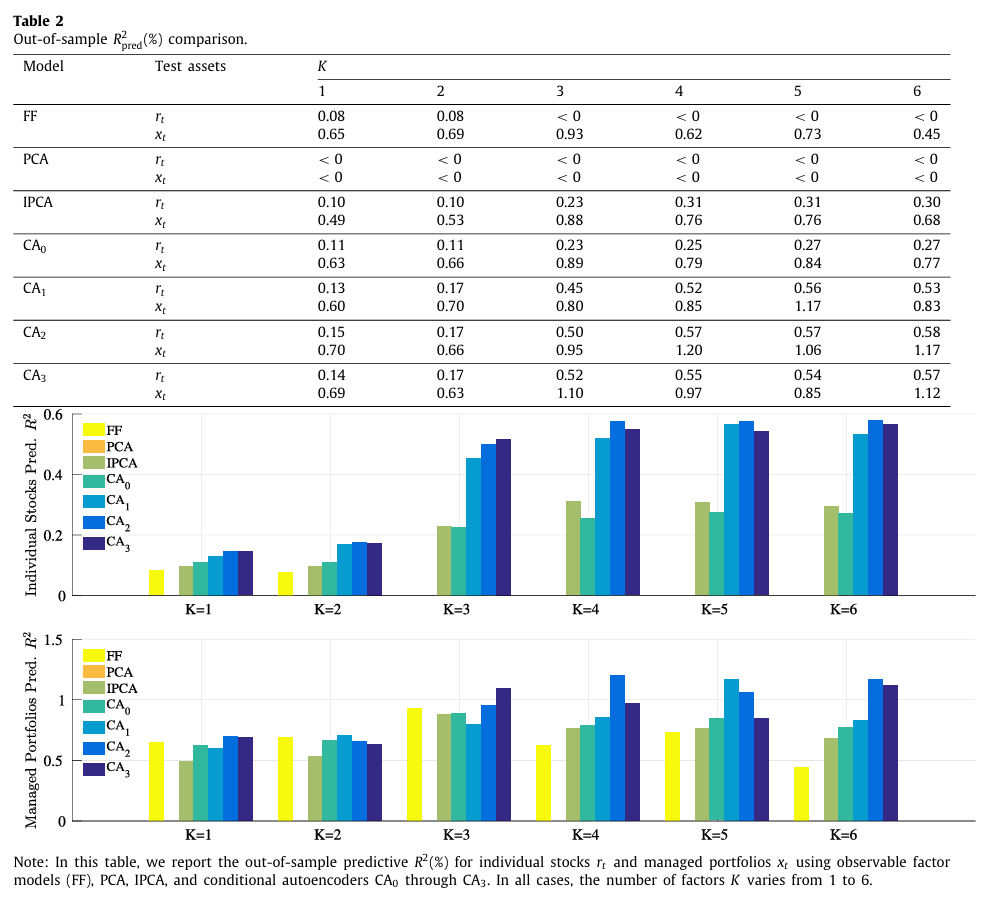
표 2에서는 개별 주식 및 특성 포트폴리오의 Predictive R-square 값을 나타낸다.
- Total R-square에서의 결과와 다르게, CA가 다른 모델들을 모두 압도하며 IPCA보다 약 두배 가까이 높은 설명력을 보인다. 또한 정적 모델인 FF와 PCA보다도 여전히 훨씬 뛰어난 성능을 보인다.
3.4. Economic performance evaluation
R-square만으로는 모델의 경제적인 기여를 추정하는 것이 어렵기 때문에, 경제적 관점에서 모델 성능을 평가하기 위해 각 모델의 수익 예측을 기반으로 구성된 포트폴리오의 샤프비율을 비교한다.
각 모델에 대해, 모델의 OOS 수익 예측을 기준으로 주식을 10분위수로 나눈 후 기대수익률이 가장 높은 10분위수는 매수, 가장 낮은 1분위수는 매도하는 제로 투자 포트폴리오를 구성한다. 이때 포트폴리오는 매월 리밸런싱하며, 동일가중과 가치가중 포트폴리오 모두를 고려한다.
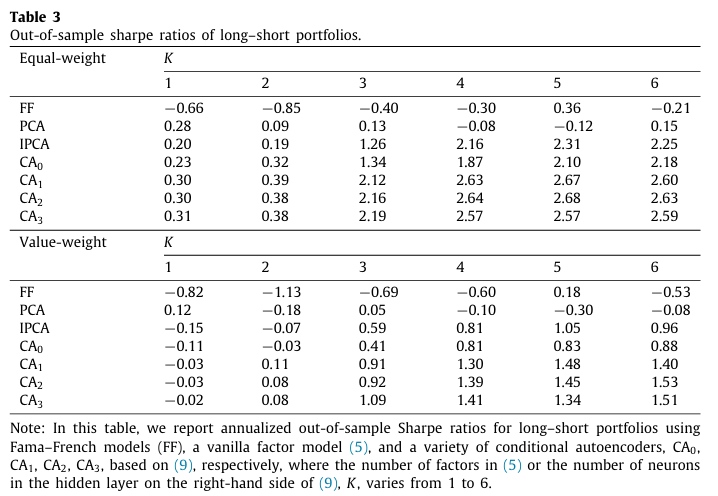
표 3은 30년간 OOS 기간동안 만든 제로투자 포트폴리오의 샤프비율을 비교한 표이다.
- 전체적으로 가장 성능이 좋은 포트폴리오는 $CA_2$ 로, 동일가중 포트폴리오에서는 2.63을, 가치가중에서는 1.53을 기록했다.
- 그 다음으로 IPA가 높고, 정적 선형모델인 FF와 PCA는 전반적으로 낮은 OOS 포트폴리오 성능을 나타낸다.
또한 각 모델의 multi-factor 평균-분산 효율성을 평가하기 위해, 팩터 포트폴리오 간의 ex ante 무조건부 tangency portfolio의 샤프비율을 비교한다.
동일하게 OOS 기간동안 팩터 수익률을 계산하여 t시점의 팩터 표본 평균 및 공분산을 구한 후 tangency portfolio를 구하여 t+1 시점의 실제 수익률을 계산한다.
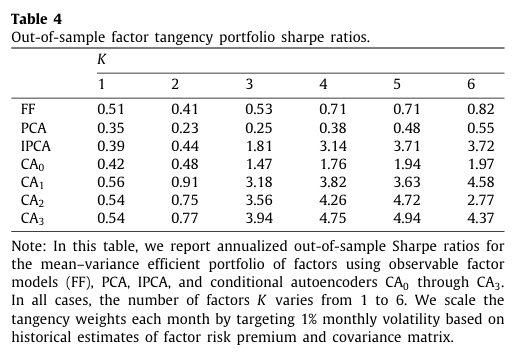
표 4를 통해 위에서 진행한 실험의 결과를 보고한다.
- 모든 조건부 팩터(IPCA 및 CA)의 tangency portfolio는 높은 샤프비율을 나타내는 반면 정적 팩터 모델은 현저히 낮은 성능을 보인다.
→ 이러한 결과는 조건부 모델이 자산 간 광범위한 공통적 움직임을 포착하면서 동시에 자산 간 평균 수익률의 차이를 팩터 로딩을 통해 설명한다는 사실을 반영한다.
3.5. Risk premia vs mispricing
Gu et al.,(2019)의 수익률 예측 분석에서는 가장 예측 성능이 좋은 머신러닝 모델이 0.4%의 Predictive R-square 값을 나타냈다. 하지만 그 모델은 순수 예측 모델에 불과하기 때문에 예측이 팩터 노출에 대한 보상(Risk premia)에서 비롯되는지, 알파(mispricing)로부터 비롯되는지를 구분할 수 없다.
반면 본 논문에서는 알파를 0으로 설정하고 모든 특성 기반 예측 가능성이 오직 팩터 노출을 통해서만 나오도록 강제하였는데, 이러한 제약에도 불구하고 조건부 오토인코더 모델은 월별 주식 수익률 예측 능력에서 거의 동일한 성과를 달성하며 $CA_2$ 의 경우 Predictive R-square 값이 0.58%를 기록했다.
이는 주식 특성이 수익률을 예측하는 이유는 위험 없이 이상현상(anomalous)을 포착하기 때문이 아니라 특성이 팩터를 식별하는데 도움을 주고 팩터의 위험 노출을 대리하기 때문임을 시사한다.
이번 절에서는 무차익 조건에서의 “절편이 0이어야 한다”는 제약이 실제 데이터에서 성립하는지 직접적으로 검정한다.
만약 이 조건이 성립한다면 각 자산에 대해 모델 잔차(여기서는 mispricing)의 시계열 평균이 통계적으로 0과 구별되지 않아야 한다.
여기서는 managed portfolio $x_t$ 에 대해서 분석을 진행한다. 이는 개별 주식 수익률의 추론에 대한 어려움을 피할 수 있으며 OOS pricing error를 추정하기 위해 $x_t$ 와 모델의 OOS 결과와의 평균 차이를 계산한다.
여기서의 pricing error는 어떤 체계적 요인에 대해서도 노출이 없는 헤지 포트폴리오가 얻는 수익으로 해석할 수 있으며, 무차익 모델에서는 체계적 팩터 노출이 0인 자산은 초과수익을 얻어서는 안된다.
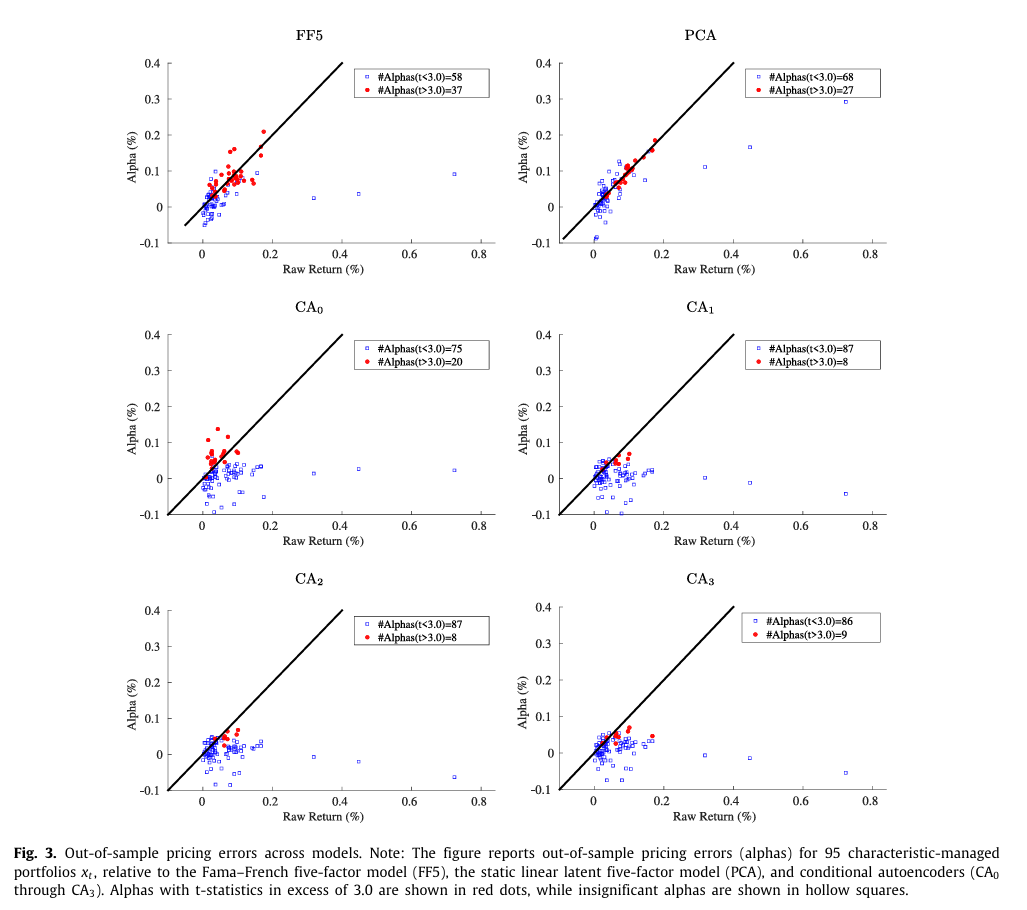
Figure 3는 각 모델에 대해 추정된 OOS Pricing error를 $x_t$ 의 평균 수익률과 비교한 산점도이다.
- 모델이 발전할수록 알파의 전체 크기가 감소한다.
- FF5 모델은 95개의 managed portfolio 중 37개의 알파의 t-statistics가 3.0을 초과하는 반면 $CA_2$ 의 경우 8개로 줄어든다.
3.6. Characteristics importance
이 섹션에서는 각 특성의 중요도를 순위화하여 영향력이 높은 공변량을 식별한다.
변수 중요도는 특정 특성의 모든 값을 0으로 설정하고 나머지 특성들로 모델을 추정했을 때 Total R-square 감소량으로 정의된다.
여기서는 5팩터 기준으로 분석을 진행한다.
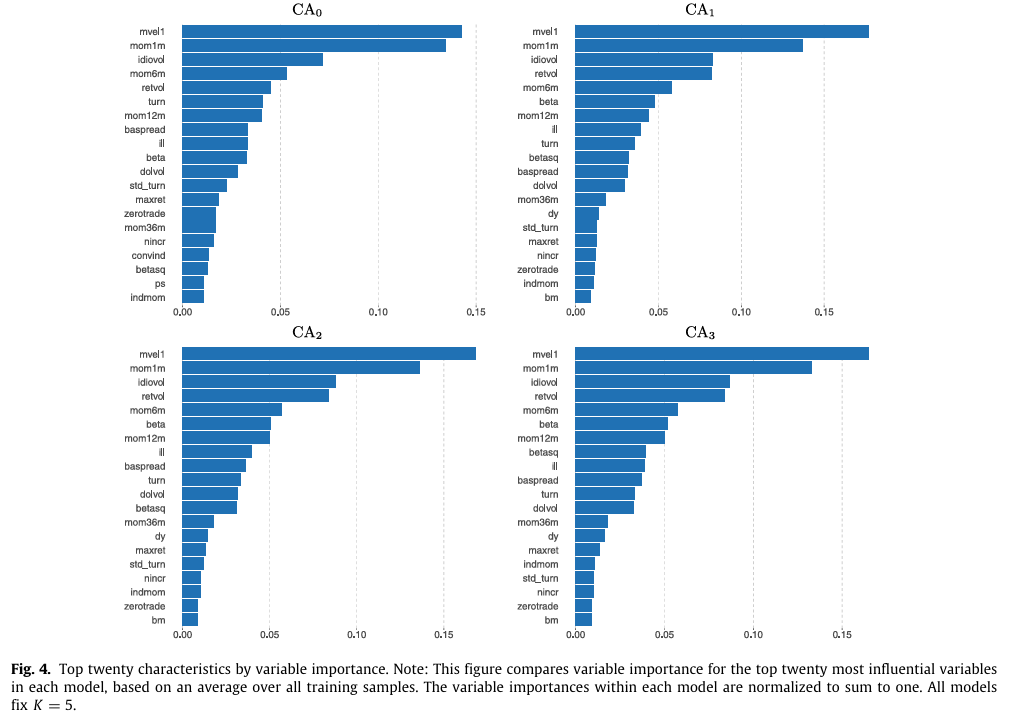
그림 4는 각 조건부 오토인코더 모델에 대한 특성의 중요도를 나타낸다.
- 상위 20개 특성을 제외하면 다른 변수들의 중요도는 거의 0에 가깝다.
- 상위 20개 특성의 총 기여도는 약 80~90%이며, 3개의 특성 범주가 가장 영향력이 크게 나타났다.
- 가격 추세: 단기 반전(mom1m), 주식 모멘텀(mom12m), 모멘텀 변화(chmom), 산업모멘텀(indmom), 최근 최대 수익(maxret), 장기 반전(mom36m)
- 유동성: 거개량(turn), 거래량 변동(std_turn), 로그 시가총액(mvel1), 달러 거래액(dolvol), Amihud 비유동성(ill), 거래 없는 일수(zerotrate), 매수-매도 스프레드(baspread)
- 리스크: 총 변동(retvol), 특이 수익 변동(idiovol), 시장베타(beta), 베타제곱(betasq)
- 모든 오토인코더 모델이 이 3개의 특성 범주의 중요성이 높게 나타났다.
→ 이러한 일관성은 주요 변수들에 대한 견고함을 나타내며, 이러한 변수들이 기대수익과 실현수익 모두의 변동을 이해하는 데 중요하다는 것을 시사함.
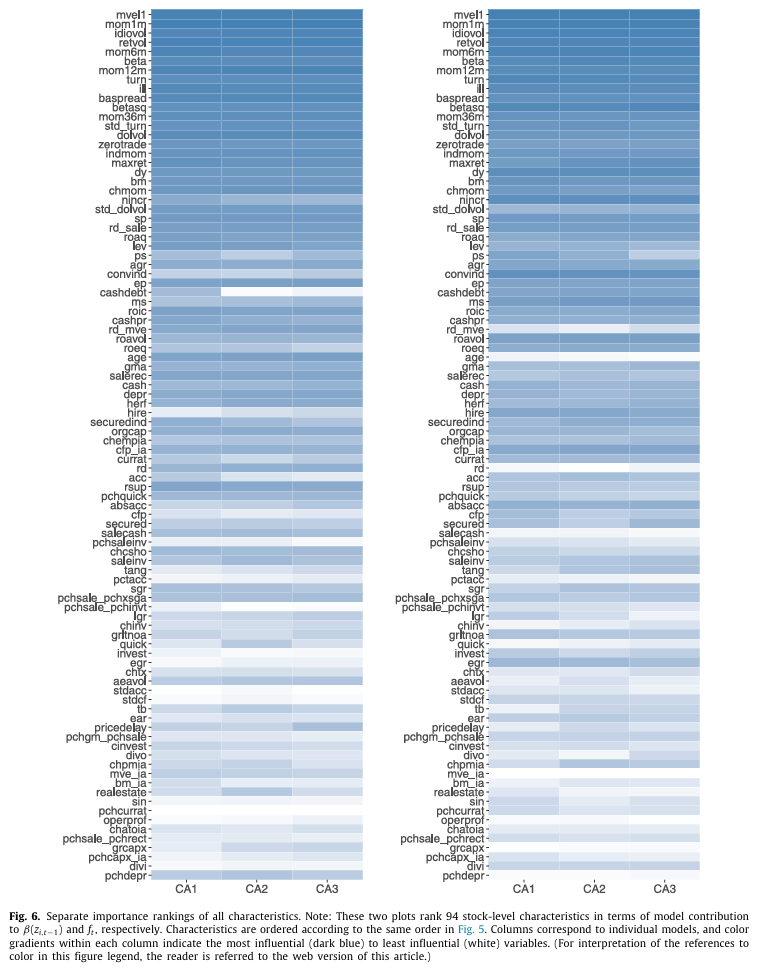
추가적으로 팩터 네트워크와 베타 네트워크 각각의 특성 중요성을 보기 위해 한쪽 네트워크의 특정 특성값을 0으로 설정하고 반대쪽 네트워크에서 이 특성의 값은 변경하지 않은 채 Total R-square 감소량을 측정한다.
- 특성의 상대적 중요성 또한 두 네트워크에서 일관되게 나타난다.
3.7. Robustness check
마지막으로 본 논문에서는 훈련 및 테스트 샘플에서 자산 선택에 대한 강건성을 입증한다.
각각 홀수 또는 짝수 permno로 구성된 주식의 하위 샘플을 사용하여 $CA_2$ 를 재훈련한다.
(permno: CRSP 데이터베이스에서 쓰는 주식 식별 번호)
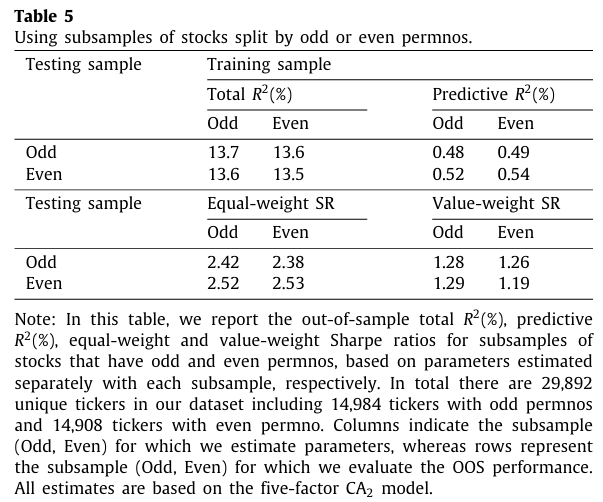
표 5는 하위 샘플에 대한 Total R-square 및 Predictive R-square 을 나타낸다.
- 훈련 및 테스트 샘플에서 사용된 자산이 겹치지 않더라도 $CA_2$ 모델은 거의 동일하게 우수한 성능을 보이는 것을 확인할 수 있다.
4. Monte Carlo simulations
이 섹션에서는 초과수익률 $r_t$ 에 대한 조건부 오토인코더 3팩터 모델을 시뮬레이션한다.
$r_{i,t} = \beta_{i,t-1} f_t + \varepsilon_{i,t}, \qquad \beta_{i,t-1} = g^{*}(c_{i,t-1}; \theta), \qquad f_t = W x_t + \eta_t$
여기서 $c_t$ 는 N by $P_c$ 특성 행렬이고 $f_t$ 는 3 by 1 팩터 벡터, $x_t$ 는 $P_x$ by 1 팩터 구성요소 벡터, W는 3 by $P_x$ 가중치 행렬, $\eta_t, \epsilon_t$ 는 각각 3 by 1, N by 1의 idiosyncratic error 벡터이다.
각 파라미터 및 변수의 분포 가정은 다음과 같다.
$x_t \sim \mathcal{N}(0.03,\; 0.1^2 I_{P_x}), \qquad \eta_t \sim \mathcal{N}(0,\; 0.01^2 I_{3}), \qquad \varepsilon_{i,t} \sim t_{5}(0,\; 0.1^2)$
이때 이들의 분산은 평균 시계열 $R^2$ 가 약 45%, 평균 연율화 변동성이 약 60% 가 되도록 조정한다.
$c_{i,j,t} = \frac{2}{n+1} , \quad rank(\tilde c_{i,j,t}) - 1$
$\tilde c_{i,j,t} = \rho_j \tilde c_{i,j,t-1} + \epsilon_{i,j,t}$
→ 특성값 랭크 기반 정규화([-1,1] 범위로 정규화), AR(1) process 가정
$\rho_j \sim U(0.9,1), \quad \epsilon_{ij,t} \sim N(0,1)$
추가적으로 하나의 고정된 행렬 W와 총 2개의 팩터로딩 구조를 고려한다.
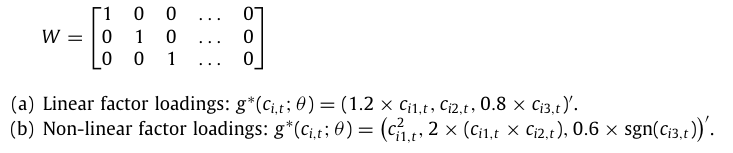
N = 200, T = 180, $P_c = P_x = 50$ 으로 고정하였으며, 두 경우 모두 3개의 특성만이 $g^*(.)$ 에 의존하므로 0이 아닌 3개의 변수만 존재하며, 이는 $\theta_0$ 으로 나타낸다.
Case (a)는 단순하고 희소한(sparse) 선형 모형이지만 Case (b)는 비선형 모형으로, 다음과 같은 요소를 포함한다.
- 비선형 공변량 $c_{i1,t}^2$
- 비선형 interaction term $c_{i1,t} \cdot c_{i2,t}$
- 더미 변수 $sgn(c_{i3,t})$
$\theta_0$ 의 값을 Total R-square가 약 40%, Predictive R-square가 약 5%가 되도록 보정하였다.
각 몬테카를로 샘플에 대해 전체 시계열 데이터를 길이가 동일하도록 훈련, 검증, 테스트 셋으로 분할하였으며 PCA와 IPCA의 경우는 튜닝 파라미터가 없기 때문에 학습과 검증 셋을 합쳐서 사용했다.
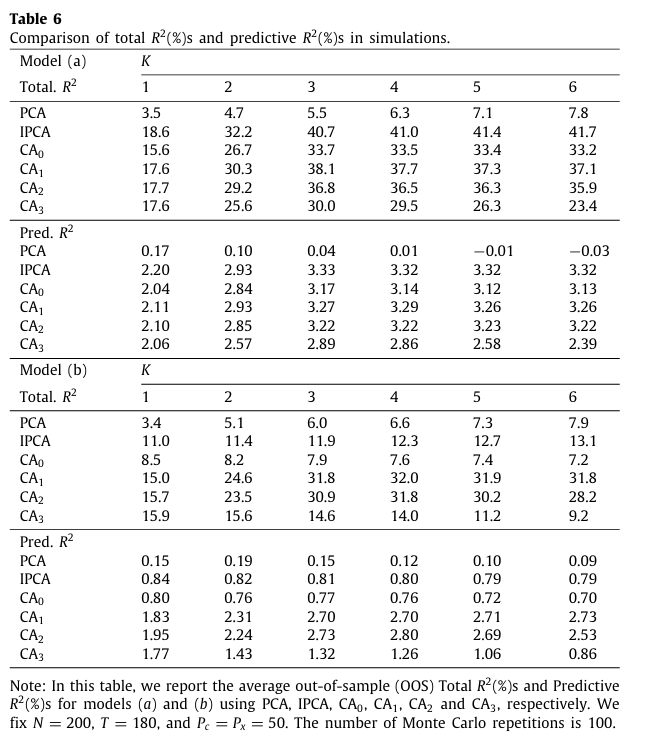
표 6은 총 100번의 몬테카를로 반복 실험을 통해 평균 OOS Total R-square과 Predictive R-square을 비교한 표이다.
- Model (a) 에 대해서는 생성 구조가 선형이었기 때문에 CA 모델이 과적합으로 인해 IPCA보다 성능이 비교적 낮게 나타난 것을 확인할 수 있다.
- 반면 Model (b)에 대해서는 데이터 생성 모형이 비선형이고, CA를 제외한 다른 모델들은 이러한 비선형 구조를 포착할 수 없기 때문에 CA모델의 성과가 더 좋은 것을 보였다.
- 오토인코더 모델 간 비교는 모델의 유연성과 구현 난이도 사이의 뚜렷한 trade-off 관계를 보였다.
→ 더 얕은 구조의 CA 모델이 더 좋은 성능을 보이는 경향이 있으며 이는 실증 분석 결과와도 일치한다.
전체적으로 시뮬레이션 결과를 통해 조건부 오토인코더 방법이 선형 및 비선형 상황 모두에서 팩터 구조를 성공적으로 학습할 수 있음을 시사하며, 이는 팩터 로딩의 함수 형태를 더 복잡하기 함으로써 적합도와 예측력이 개선되도록 설계되었기 때문이다.
5. Conclusion
본 논문에서는 오토인코더를 활용하여 latent factor model을 구축하였다.
표준 오토인코더를 활용하여 latent factor와 factor loading을 자산 특성에 의존하도록 만들었으며, 결과적으로 무차익 가정에서의 비선형 조건부 asset pricing 모형을 제시했다.
이 모델은 기존 asset pricing 모델들을 모두 능가하는 성과를 보였는데, 모델의 설명력 뿐만 아니라 팩터모델이 예측한 주식수익률을 기반으로 만든 롱숏 포트폴리오의 성과 및 팩터 tangency portfolio 또한 높은 성과를 보였다.
마지막으로, 제시한 팩터모델이 기존의 Fama-French 팩터모델보다 자산의 mispricing 정도가 훨씬 작다는 결과를 보였다.
6. 리뷰를 마치며
이 논문은 factor model 관련 논문에서 딥러닝 구조를 사용하여 탑저널에 실린 굉장히 유명한 논문인데, 일단 정말 많은 데이터를 사용하여 분석을 강건하게 진행했다는 점이 놀라웠다.
또한 기존의 팩터 모델의 경제적인 구조를 유지하기 위해서 팩터 네트워크는 선형층을 사용했다는 점이 굉장히 인상깊었는데, 딥러닝을 사용할 때도 항상 경제적인 해석이 가능하도록 해주는 것이 매우 중요하다는 것을 배웠다.
개인적으로 Decision-Focused Learning에 팩터 모델을 결합하는 연구를 고안중인데, 이 오토인코더 모델을 사용한다면 포트폴리오 결정에 효과적인 팩터구조를 만들어줌으로써 포트폴리오 성과를 더 높일 수 있지 않을까 생각이 들었다.